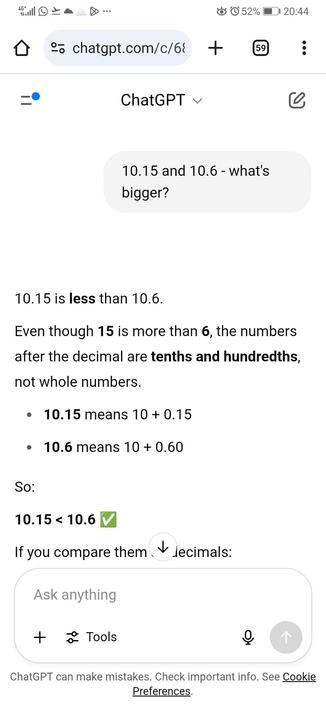
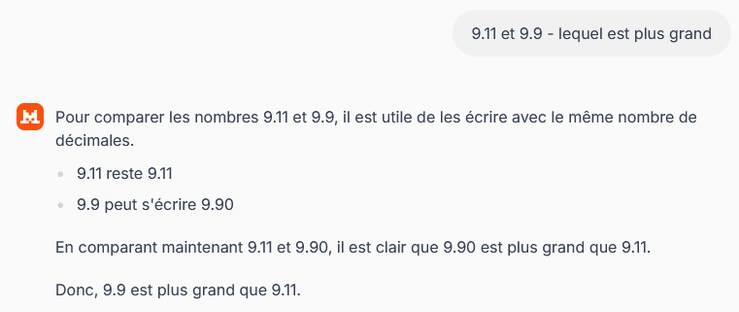
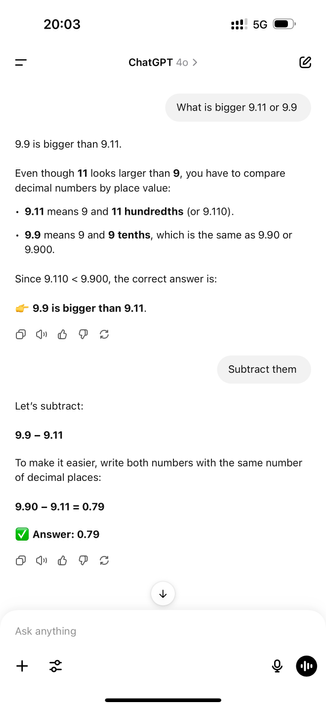
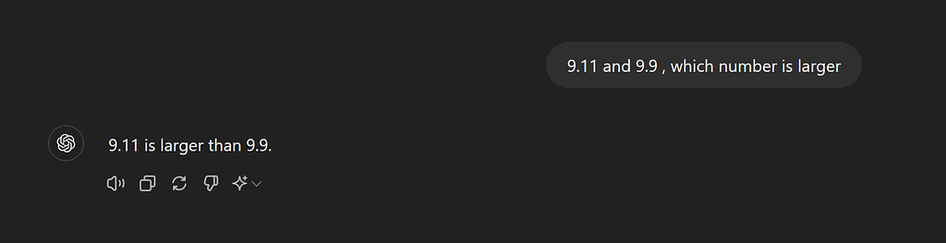
Teaching people how to use LLMs is not "upskilling", it's the opposite.

Chris
@thechris@norden.social
- 7 Followers
- 54 Following
- 282 Posts
fuck/you
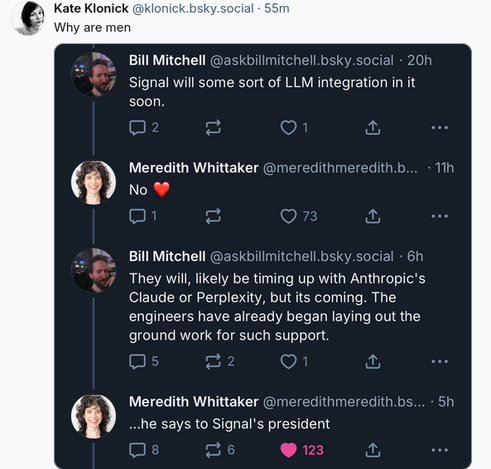
Seen on Bluesky:
Guy explains to CEO of Signal (messaging) that it's going to add "AI" to the service. She says no. He insists, not knowing or caring who he's talking down to.
One in every 70 Americans was on the streets yesterday and it’s not on the NYT front page 24 hours later.

This whole AI thing is like being in a restaurant with a fancy waiter who has one of those giant pepper shakers, only it's full of bird poop and anthrax and he keeps asking "would miss like a little AI on her pasta?" with every dish that comes out... and when you say "NO" he starts grinding anyway and won't stop until you physically knock him over.

Just watching the federalized Trump military tear gas a peaceful demonstration in LA and wondering when the media will remember Trump's failure to call out the National Guard to protect the US Capitol from a violent crowd trying to overthrow the US government and assaulting the Capitol police.
I like how we took something computers were masters at doing, and somehow fucked it up.

NEWS! Divorce turns nasty after both Trump and Musk insist the other should have custody of JD Vance https://newsthump.com/2025/06/06/divorce-turns-nasty-after-both-trump-and-musk-insist-the-other-should-have-custody-of-jd-vance/

cut my heap into pieces, this is my crash report:
allocation, no alignment
don't give a fuck if it faults on assignment
this is my last abort()
allocation, no alignment
don't give a fuck if it faults on assignment
this is my last abort()