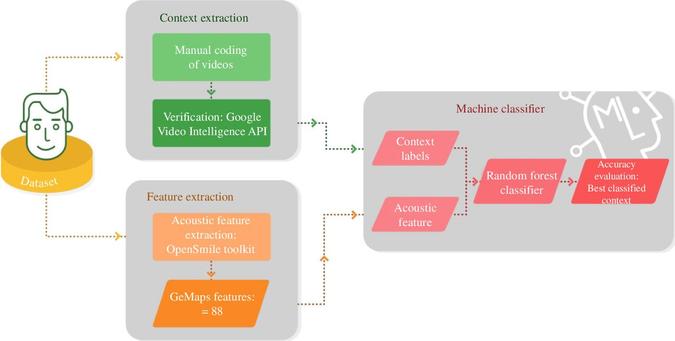
Delighted that a project that took shape within a #machinelearning
workshop at the @eScienceCenter and which was initiated and led by #RozaKamioglu
and #DisaSauter resulted in a data analysis of human #laughter sounds.
--> https://royalsocietypublishing.org/doi/10.1098/rsbl.2024.0543#d1e1021