Sound Advice from the White Knight
Bruce and I seem to be on a “language matters” kick recently, debating proper use of switch vs router and obsessing over the precise meaning of virtualization. That’s not going to change this week, as we tackle one of the most nuanced topics in networking: naming. As the White Knight explains to Alice in Lewis Carroll’s Through the Looking-Glass, it’s important to distinguish between what a song is, what it is called, what it is named, and what the name is called. Carroll was a pen name for Oxford mathematician Charles Dodgson, and so he surely understood the nuances of that passage.
If that seems like an odd place to start a post on naming, I was reminded of the White Knight’s dialogue as I re-read John Shoch’s classic Inter-Network Naming, Addressing, and Routing paper, where he uses it to motivate the following distinctions:
- a name identifies what object we want to access,
- an address identifies where the object is located, and
- a route identifies how to reach (connect to) the object.
Those three statements are familiar to every student of networking, and as seductively simple as they sound, precise definitions of these terms turn out to be quite elusive (as Jerry Saltzer pointed out in 1982). I ended up relearning that lesson for the umpteenth time as I worked on the Naming Systems chapter for 7E.
I came to realize that one of the problems we have with Shoch’s definitions, especially as we’ve rationalized ways that they apply to modern situations, is that we’ve forgotten the context in which he wrote them. In 1978, it wasn’t so much that Shoch was trying to give precise and timeless definitions for the three terms, but rather, he was simply reminding us not to conflate the three concepts. This was a time when email might be sent to someone with an address of the form ucbvax!decwrl!bob%office@arpa. In effect, users identified people they wanted to send email to with what amounted to a route across the network. Shoch was spot on: identifying what resource you want is, in fact, separable from determining where that resource is currently located, which is in turn separable from deciding how best to reach that address. Beyond that, reading too much into those particular definitions can quickly lead you down a rabbit hole.
Jumping ahead to a modern-day version of those definitions, I’ve personally never fully grasped the distinction between URIs, URLs, and URNs. Yes, I know how they’re defined (Uniform Resource Identifiers, Locators, and Names), but I’ve never fully understood the distinction at the level the White Knight insists I understand it. After working on the Naming chapter, I think I now do, and the answer is clear-cut.
URIs, URLs, and URNs
First to dispense with the easy part: URI is the generic term; URLs and URNs are two subsets of all URIs. What’s important about URIs is that they codify a uniform syntax for composing a federation of existing naming systems. That uniform syntax is what was missing from those early addresses (e.g., ucbvax!decwrl!bob%office@arpa), which effectively tried to federate disjoint “email domains” in an ad hoc way. That lack of a coherent syntax worked to my favor since I did a dissertation on the topic of how to model arbitrary naming systems, but we’re much better off with a uniform way to compose namespaces to create a universal naming scheme.
As for URLs and URNs, everyone understands that the “L” stands for “Locator” and “N” stands for “Name” but exactly what property distinguishes a locator from a name is as elusive as what distinguishes an address and a name. It seemingly depends on your context, which makes sense: all identifier bindings are resolved within some context. (The centrality of context is the main lesson of Saltzer’s seminal paper.)
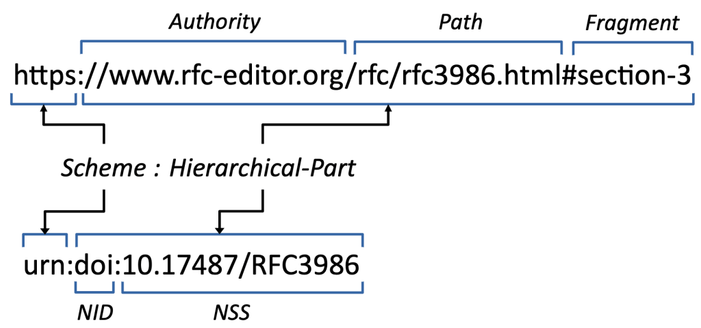
Taking a few liberties for expediency, the following diagram shows the general form of all URIs, with further details spelled out for an example URL (top) and URN (bottom):
The https scheme is most familiar. The hierarchical part begins with a naming authority that is responsible for resolving names in the remainder of the URI. The path component is also a hierarchical name, for example, a file name. The fragment component, if present, identifies a secondary resource within the primary resource, such as a subsection of a document.
In addition to the syntax of the hierarchical part, a scheme also specifies a corresponding action. This action is what gives the hierarchical part meaning (i.e., defines its semantics). Since URIs are typically processed by a browser, we can think of this action as being executed by the browser:
- https://… the browser opens an HTTPS connection
- mailto:… the browser launches an email client
- ftp://… the browser opens an FTP connection
- file://… the browser asks the OS to open a file
- urn:… there is no action for the browser to execute
The lack of an action for the urn scheme may be surprising, but by definition, if we knew a way to access the resource, the URI would be a URL and not a URN. So what are URNs good for? We’ll explore that question in a moment, but as for its syntax, the first thing to notice is that the example uses urn to identify the scheme. This is an example of a URN-compliant scheme (there are others), but the urn scheme was established as an exemplar for other schemes to follow.
The hierarchical part consists of an NID (Namespace Identifier) and an NSS (Namespace String). The NID, doi in the example, is registered to the Digital Object Identifier Foundation, an organization established to serve as a registration authority for names/identifiers assigned to any-and-all digital, virtual, and physical resources. In the example, the DOI is able to resolve the name 10.17487/RFC3986, where prefix (10.17487) identifies a sub-authority (in this case the RFC Editor), and the suffix (RFC3986) uniquely identifies a specific RFC. The IANA is responsible for maintaining both the set of valid schemes and the registry of official NIDs under the urn scheme; doi is registered as both.
As for the question about why URNs exist in the first place, the answer is to meet the requirement that an object’s name be permanently bound to the object. Where an object is located and how it is accessed—and hence, its URL—may change, but there are circumstances in which we need to officially record that the object remains the same.
The physical world is full of documents and other objects that for legal and other reasons need to be uniquely identifiable over time. A great example is the ISBN (International Standard Book Number) assigned to books and other published material. When it became clear that the Internet had the potential to support arbitrary digital objects, it followed that the Internet also needed to establish a digital identifier for those objects. Bob Kahn and colleagues designed such a naming service, called the Handle System, which eventually influenced the inclusion of URNs in the URI definition. It also led to the creation of organizations like the DOI to register and manage these persistent names.
All of this results in the following being legitimate URIs for the example digital object I’ve been using as a running example:
- urn:doi:10.17487/RFC3986 — a URN, with urn as scheme and doi namespace
- doi:10.17487/RFC3986 — a URN, with doi as scheme
- urn:ietf:rfc:3986“ — a URN, with urn as scheme and ietf namespace
- https://doi.org/10.17487/RFC3986 — a URL, with https as scheme
- https://www.rfc-editor.org/rfc/rfc3986 — a URL, with https as scheme
If you try each of these in your browser, you will find that only the last two return something meaningful, which if nothing else, gives us a clear-cut operational distinction between URNs (names) and URLs (addresses). This is because only the https scheme triggers a protocol capable of actually locating and retrieving content. Requesting the doi.org URL resolves the object’s URN, returning a 302 Redirect code pointing to the set of metadata associated with RFC 3986 (as opposed to the RFC itself). This metadata includes links to various representations of the RFC, including an HTML version. The last URL above is for that web page, and so accessing it displays the RFC. In other words, the DOI site, which is based on the Handle System, returns a “representation” of the named object, specifically an information page containing the relevant metadata. Technically, a handle-based URN names an abstract resource, not necessarily the HTML web page. The White Knight would surely approve.
This story about trailing dots in hostnames from curl maintainer Daniel Stenberg is a telling example of just how much the context in which a name is used matters. Daniel also had a great piece on just how little Mythos was able to uncover when turned loose on his very well-tested code.
Rob Ricci took a tour of data centers in the Salt Lake City area and reported his findings in the context of the Stratos mega datacenter proposal.
Peter G. Neumann, computer science pioneer and longtime moderator of the RISKS digest, has passed away at age 93.
Preview Image this week by Bruce.