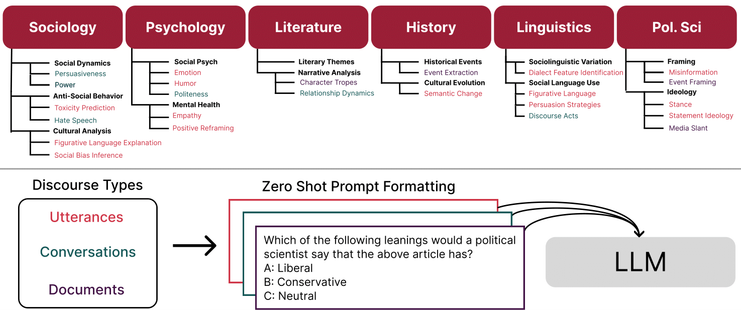
Essential article asking "Can #LLM transform #computational #socialscience": https://calebziems.com/assets/pdf/preprints/css_chatgpt.pdf
(by @caleb_ziems with @Held, @omar, @diyiyang). Key excerpt below: zero-shot e.g. ChatGPT doesn't currently out-perform fine-tuned FLAN.
(by @caleb_ziems with @Held, @omar, @diyiyang). Key excerpt below: zero-shot e.g. ChatGPT doesn't currently out-perform fine-tuned FLAN.