Named Tensor Notation (TMLR version, https://arxiv.org/abs/2102.13196)
A rigorous description, opinionated style guide, and gentle polemic for named tensors in math notation.
* Macros: https://ctan.org/tex-archive/macros/latex/contrib/namedtensor
Named Tensor Notation is an attempt to define a mathematical notation with named axes. The central conceit is that deep learning is not linear algebra. And that by using linear algebra we leave many technical details ambiguous to readers.


Named Tensor Notation
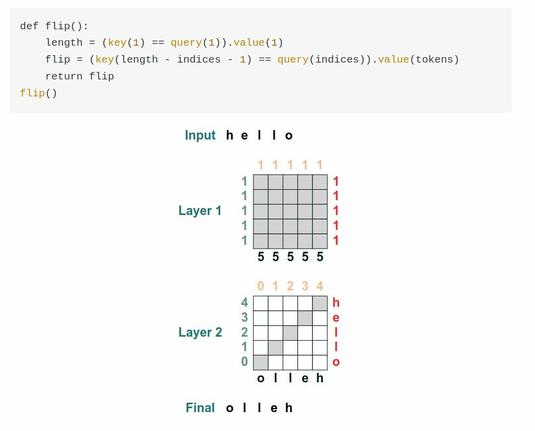
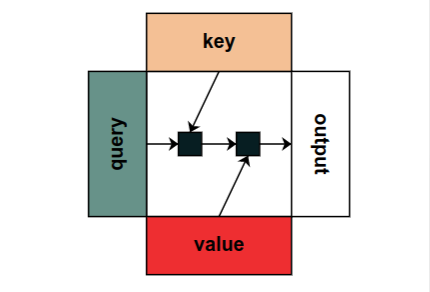
We propose a notation for tensors with named axes, which relieves the author, reader, and future implementers of machine learning models from the burden of keeping track of the order of axes and the purpose of each. The notation makes it easy to lift operations on low-order tensors to higher order ones, for example, from images to minibatches of images, or from an attention mechanism to multiple attention heads. After a brief overview and formal definition of the notation, we illustrate it through several examples from modern machine learning, from building blocks like attention and convolution to full models like Transformers and LeNet. We then discuss differential calculus in our notation and compare with some alternative notations. Our proposals build on ideas from many previous papers and software libraries. We hope that our notation will encourage more authors to use named tensors, resulting in clearer papers and more precise implementations.