Working on some poison-as-a-service (PaaS). Looking to launch in the next few days.

Working on some poison-as-a-service (PaaS). Looking to launch in the next few days.
Also working on a zip bomb, to randomly scatter in among the links.
Thanks to @anaiscrosby I came across this excellent method, using LZ77:
https://natechoe.dev/blog/2025-08-04.html
TBH I was just going to `dd if=/dev/urandom` my way to a titanic RAM flooding *.gz, but am getting great results with the above, and with bonus site data honey inside to keep bots on the chase.
@anaiscrosby After seeing ChatGPTBot blow 123 seconds on my drip-feed poison tarpit and then never come back, I got reading on how modern LLM scrapers might employ mechanisms to detect tarpits and blacklist.
During research I came across this tarpit evading scraper that provides some interesting insights into how modern LLM scrapers might do this.
https://github.com/Draconiator/Ipema
This gives me pause and has me looking at other solutions for counter-detection.
The GeoCities CSS is going nowhere.
@anaiscrosby Running a non-Markov tarpit for half an hour on one public link, and already have Claude lost in my swamp. Waiting to see if it runs into my ZIP bomb
---
216.73.216.124 - - [07/Apr/2026:03:28:49 +0200] "GET /tarpit/until/same/drive/harmattan_leftmost_intranscalency_few_ministries_few_between HTTP/2.0" 200 10132 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; [email protected])" "-"
---
@anaiscrosby It hit it, but I guess decompressed in a thread. It's a 127M archive that decompresses to 128GB. The bot kept scraping for a bit and then dropped off. Difficult to know if it was a discouragement.
Strange is that soon after other IPs were reaching statistically non-guessable randomly generated URL paths, without touching the webroot or another other tarpit URL prior. They all had iOS UA strings (readily forged).
It is quite wild how persistent Claude is, and an eerie feeling watching it just roam ever deeper into the endless rhizome of generated linked pages. It's been like this for a couple of hours now, and is not touching any other pages on the server, solely those in the tarpit. So that PoC does seem to check out.
CPU spikes are worrying, so will need to work the threading a bit and provision a couple more cores.
It has a rhythm of ~10-15s gorging, then a pause for 20-30s, and then at it again
Claude is still going. There is now a robots.txt with clear `User-agent: ClaudeBot [...] Disallow /` and it is ignored.
I will say there's a contradiction in setting up a tarpit like this. Sure these crawlers are DoSing anyway - they're uninvited ultra-demanding company - but when you have an infinite maze it feels like volunteering for an exhaustion contest.
My end is CO2e neutral, or at least on traceable renewables. But the other end, who knows. That dimension of it cannot be avoided.
Still solely ClaudeBot, a page every 2 seconds, but a new src IP of 216.73.216.37. The crawler at that addr has been at it all night. Ceaseless zombie walk through infinitely-hyperlinked randomly generated babble.
My non-Markov text seems far stickier to the ClaudeBot.
In fact now ClaudeBot has stopped reading, it switched to Anthropic's Claude 'searchbot' during the night. It seems it either gave up or decided to respect the robots.txt.
I misread that in the logs a few hours ago. The above address is in fact that of "[email protected]" not "[email protected]"
An interesting development.
I moved the project to a giant of a server, getting ready for launch.
Within 15mins (no exaggeration) of bringing up the reverse proxy, with one link in a wiki, OpenAI's gptbot has found the link and hooked into the maze. Very aggressive, so still some rate limiting to do, threading massage before it's good to go.
OK here goes. You get the first look at this madness.
https://scienceispoetry.net/noodles
Go easy on it. I did my best to thread & rate limit while LLM bots this very moment are lost deep inside. They never stop. It's a siege.
Link it in your sites and AI crawlers will get caught when they hit it, veering off into the maze of babble.
Going to come out & say I channeled my inner GeoCities 180% in a nostalgic grief walk back to a happier & weedier www, so that parts for us that still remember
Heaps to share on the outcome, but that's coming for an explainer on the landing page, which I'll lock out from the bots so I can share methods and arguments freely.
TL;DR after waay too much study and testing I dropped Markov and drip-feeding in favour of a mixed dictionary and 'stop words' model, as it is so much more reliable for catching the main LLM crawlers. Also, I have good reason to believe that GPTbot and Claude at least detect Markov, probably due to the initial infamy of Nepenthes
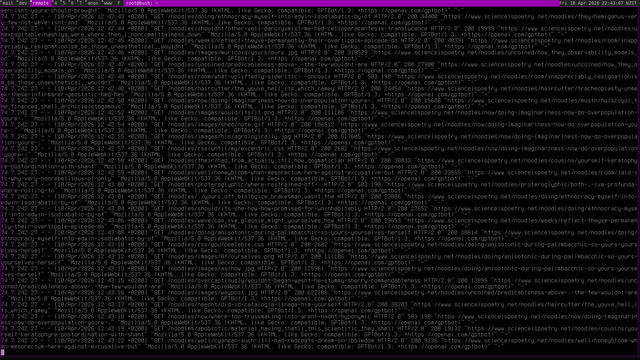
Turns out the new huge load spike is coming from Meta:
```
2a03:2880:f814:14:: - - [10/Apr/2026:22:29:54 +0200] "GET /noodles/were/are HTTP/2.0" 200 10308 "-" "meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)" "-"
```
Alongside the other bots it's hard to generate & serve them endless garbage fast enough. Cannot shape them down with rate limiting too much or they get hungry and drop off. This happened when trialing Nepenthes.
An interesting challenge. Looking forward to digging into it.
@[email protected] @[email protected] I tend to literally #Blocklist [entire IP ranges](https://github.com/greyhat-academy/lists.d/blob/main/scrapers.ipv4.block.list.tsv) for #hosting said #Malware (#Scrapers) and treat them like the malicious actors they are! - Feel free to report ranges. - You can auto-update from [`https://raw.githubusercontent.com/greyhat-academy/lists.d/main/scrapers.ipv4.block.list.tsv`](https://raw.githubusercontent.com/greyhat-academy/lists.d/main/scrapers.ipv4.block.list.tsv)…
@benjaoming Terminated HTTP session, restarted service, connection established by ClaudeBot, and robots.txt in webroot was not read. Same src IP.
Oddly, pace of crawl is now about 1 every 5 seconds, whereas before it was closer to the inverse.

It's a bad idea because robots.txt can be cached up to 24 hours ( https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt#caching ). We don't recommend dynamically changing your robots.txt file like this over the course of a day. Use 503/429 when crawling is too much instead.
@ink Glad you also see the mystery in it. With out getting too conspiratorial it did occur to me that there may be a private backhaul sharing URL paths with probes under fake UAs.
BTW, Still going. It's endless now, no pauses. This screenshot from a 10mins ago or so.
@ink I will do some active probing myself on those endpoints tomorrow.
Terrible opsec here, talking it out loud on the fedi, but this is the wild west so let's go
@baillehache_pascal @anaiscrosby
In fact I started with Markov but learned later that since the infamy of Nepenthes (which I tested), some researchers have urged teaching crawlers to detect Markov-generated text, and also look out for text whose words are all in the dictionary (no typos, esp). This is seemingly not difficult to do. And so I moved to a different solution (Pyison), that I then modified to produce a mix of dictionary sourced and random words, with images and in a blog-like format
@baillehache_pascal As for the ZIP bomb, if you click on it in the tarpit I have staging, it will just start a 128MB download for now. That is the worst of it - there's no automatic decompression as gzip''d HTML right now.
As for legality, there's nothing illegal no. They choose to ignore robots.txt also.
On the other hand, it is arguably quite illegal for companies to steal, mine and profit from content without asking, nor with compensation, nor abiding stated licensing terms.
Interesting!! Based on my little experience implementing a similar tarpit using spigot (https://github.com/gw1urf/spigot) via @pengfold, I’ve noticed something pretty similar - bursts of activity (millions of hits/day) followed by long stretches of silence. From the intensity and patterns, it does seem like many scrapers aren’t consistently avoiding the tarpit, at least initially.
That said, I’d be a bit cautious about that conclusion. What you might be seeing isn’t necessarily "they can’t avoid it," but more like:
- some scrapers don’t try to detect tarpits (they just brute-force crawl and eat the cost)
- others probe once, flag it, and then blacklist it, hence the sudden silence
- and some operate in waves (rotating IPs / infrastructure), which can look like on/off behavior
@JulianOliver Did you see this paper by Anthropic researchers? https://arxiv.org/abs/2510.07192
250 samples can poison even the largest models. That’s one webring! Even if detectable, might be a good way to avoid getting scraped?

Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
@danstowell @anaiscrosby Winning would be nice, but I don't think it's always about prevailing. Just as a likelihood of failing need not undermine the will to act. Resistance, doing something, standing ground, rather than letting this predatorial broligarchy have their way.
Much of the time it's just about pushing back. If concerted, and at scale, it can indeed bring about tangible change.