One of the ways that LLM-authored code improves productivity is by merely SAYING it does things. It's way faster than the whole time-consuming process of actually doing things. This is real code someone sent to me for review.

Here is a way that I think #LLMs and #GenAI are generally a force against innovation, especially as they get used more and more.
TL;DR: 3 years ago is a long time, and techniques that old are the most popular in the training data. If a company like Google, AWS, or Azure replaces an established API or a runtime with a new API or runtime, a bunch of LLM-generated code will break. The people vibe code won't be able to fix the problem because nearly zero data exists in the training data set that references the new API/runtime. The LLMs will not generate correct code easily, and they will constantly be trying to edit code back to how it was done before.
This will create pressure on tech companies to keep old APIs and things running, because of the huge impact it will have to do something new (that LLMs don't have in their training data). See below for an even more subtle way this will manifest.
I am showcasing (only the most egregious) bullshit that the junior developer accepted from the #LLM, The LLM used out-of-date techniques all over the place. It was using:
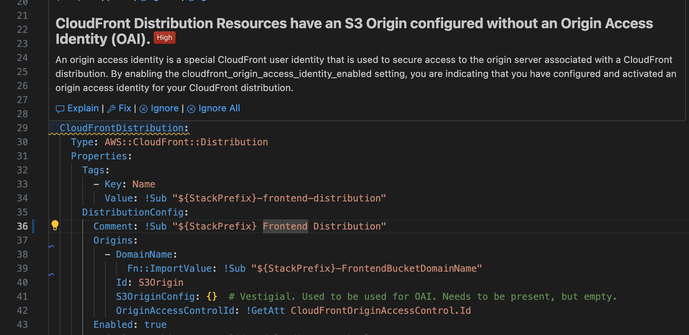
So I'm working on this dogforsaken codebase and I converted it to the new OAC mechanism from the out of date OAI. What does my (imposed by the company) AI-powered security guidance tell me? "This is a high priority finding. You should use OAI."
So it is encouraging me to do the wrong thing and saying it's high priority.
It's worth noting that when I got the code base and it had OAI active, Python 3.9, and NodeJS 18, I got no warnings about these things. Three years ago that was state of the art.
It is even worse than that, there will be a rush by folks looking to poison the data set to plant enough bad code w/ exploits they know about in the hopes that it gets seeded in some x% of code bases given them plenty of low hanging fruit to pick.
@shafik @paco Poison is a really interesting aspect of the whole LLM thing. Nightshade has only been out for a little while, and it doesn’t have a large install base, but you can already see its effects in “art” generated by the poisoned learn modality.
My point is, there are very clever people who can and will poison the llm. While image poison offers no real opportunity for shenanigans, poisoned code bases have all sorts of ways they can be exploited, including backdoors, dead drops, and key forwarding.
And if you fire the real coders, and just have devs that accept echoes as real code, then the architecture will fail spectacularly.
This reminds me of the prophet Paul Riddell who once said “We can solve a lot of problems if we club all the MBAs like they were baby seals.”
@MissConstrue @shafik @paco Also, poisoning is an object lesson in how easy it is to pollute this stuff - reminder: The vendors behind all of it CANNOT WAIT!! to start polluting it in ways that favor themselves and/or anyone who pays them enough.
The output from these systems can never be remotely trustworthy & that's a fundamental technical limitation.