Wait hold on I just realized. Is
八人入
A reasonable Chinese sentence
In Pleco they look like this. I don't know if this is a different but regular hanzi font or if the CJK unification is messing me up somehow
EDIT: I currently think Tusky is showing me Japanese character variants https://social.mildlyfunctional.gay/@artemist/116146010272716935

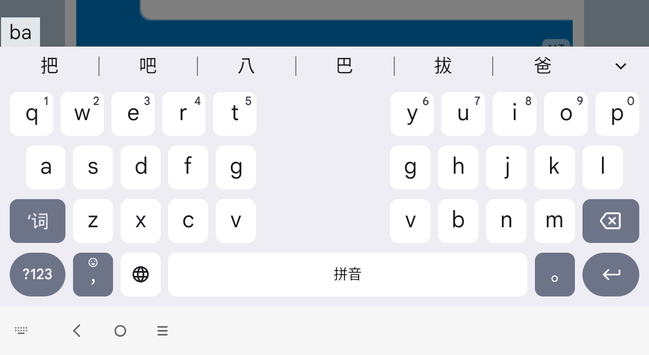
Okay I now believe the problem is neither Tusky nor Lenovo but rather that Android is not a serious product and never has been. It seems Android may outright refuse to show scripts unless you've whitelisted the language. Problem: I think this menu is asking me which version of Chinese I want but the menu is in Chinese. I want to look at Chinese text so I can learn Chinese. I don't know it yet. I feel like I'm playing an adventure game.
* I may explore a PR later anyway.
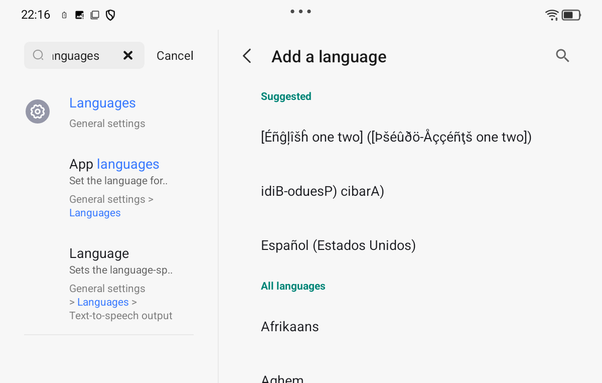
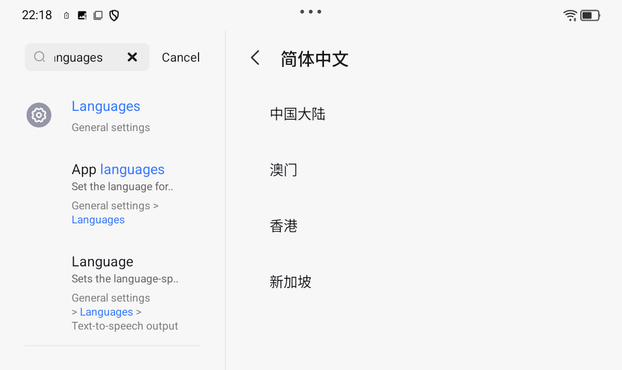

From what I understand, the 个 is not optional and must be included except that it’s entirely optional and is dropped half the time or something.
@mcc hmm, to me (learned Mandarin as a first language in parallel with English but am now extremely rusty) it reads as archaic but understandable; I think the use of 入 as a standalone verb also contributes here? like for something like “eight people entered [the room]” my natural translation would be 八个人进去了 (or 进来了, depending on my perspective)
…god I need to find an excuse to properly unrust my Mandarin
@rachelplusplus
Yeah, I remember this from doing some i18n work, and the Wikipedia article appears to agree.
@0xabad1dea @mcc I suppose the only actually reliable approach would be to store the IME locale per character or something so that it can be accurately rendered as it was written... or are these truly identical graphemes, and there's no chance of confusion in context? Even when people use multiple languages simultaneously?
(late edit after reading a lot more: ah, I see they DID just add a variant-selector character to effectively specify the locale... that seems a bit unlikely to gain major use, but technically I like it I guess)
Maybe one day we'll have UTF-8-2 and it'll just be infinitely extendable, rather than using a limited length prefix.