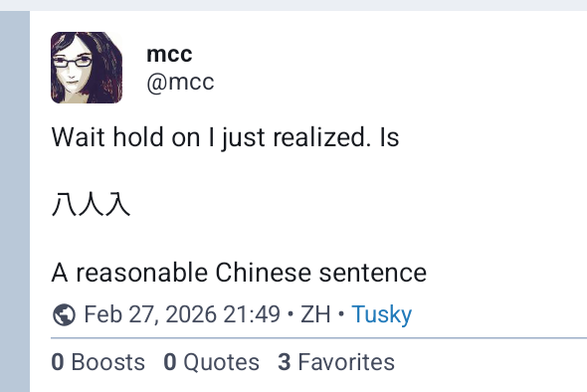
Wait hold on I just realized. Is
八人入
A reasonable Chinese sentence
In Pleco they look like this. I don't know if this is a different but regular hanzi font or if the CJK unification is messing me up somehow
EDIT: I currently think Tusky is showing me Japanese character variants https://social.mildlyfunctional.gay/@artemist/116146010272716935

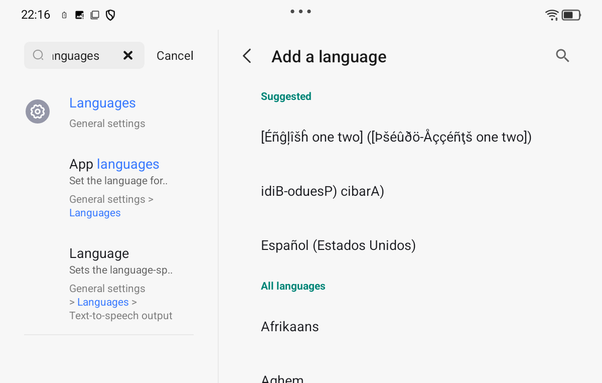
Okay I now believe the problem is neither Tusky nor Lenovo but rather that Android is not a serious product and never has been. It seems Android may outright refuse to show scripts unless you've whitelisted the language. Problem: I think this menu is asking me which version of Chinese I want but the menu is in Chinese. I want to look at Chinese text so I can learn Chinese. I don't know it yet. I feel like I'm playing an adventure game.
* I may explore a PR later anyway.

From what I understand, the 个 is not optional and must be included except that it’s entirely optional and is dropped half the time or something.
@mcc not sure about the context it'll be used in, but the choices are:
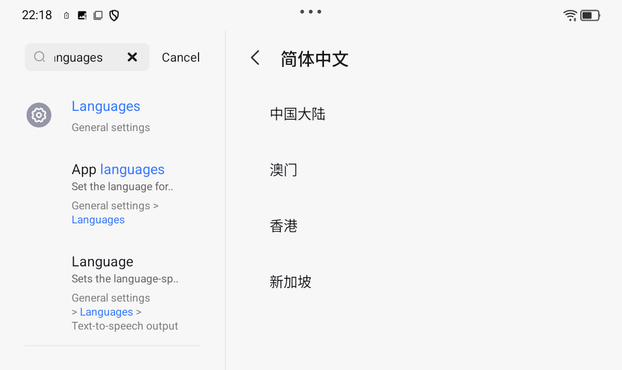
* Mainland China
* Macau (you'd never guess this without looking it up)
* Hong Kong
* Singapore
@r @mcc i mostly remember macau as "the one that has 门 in it".
Android will render text from languages not in your list, that's why pleco shows the right forms. it just won't do so unless explicitly told to with an android.text.style.LocaleSpan, which most apps don't bother to do.
You can get the same problem in web browsers if it isn't told what language to use. I regularly see japanese forms in chinese subtitles because google isn't setting lang="zh-Hans" for their subtitles.
@mcc
This is the problem with han unification; we're partway back to code pages and picking the right font to render a particular language.
Like telling Danes and Swedes that ä and æ is the same character and so we'll just make them the same in Unicode.
@jannem Mmm, not sure about that. In my experience, “text encoding” and “language” are 2 orthogonal axes, and proper text handling requires you to know both.
This is one of the minor annoyances of Mastodon — it doesn't seem to be possible to mark parts of a post as being in different languages.
I don't have a huge problem with Han unification. I think it's a valid technical decision.
@krans @mcc
The bigger problem is that on the web and in apps there's usually no information on what language something is written in. Which means a browser or an app they can only guess what font to render Unicode han characters in. And when a user has installed support for more than one it is certain to frequently go wrong.
Edit: you don't need to know the language to always render "ä" correctly. You do need to know the language in order to render "骨".
@jannem I agree. The root cause is that file formats, protocols and most programs are written almost entirely by English-speakers, who assume that only English-speaking people use computers and that all content will be in English.
For my entire lifetime, support for multilingual text has always been an afterthought — and many development frameworks make it incredibly difficult.
@mcc are you on ubuntu still?
https://www.thomasvanderberg.nl/blog/fix-cjk-font-order-linux/