the fact that the Internet Archive got into bigger trouble for lending books they paid for than Facebook did for reproducing books they pirated tells you everything you need to know about copyright.
@Yuvalne It's another example of how the legal system harshly punishes less financially well off people and businesses, while allowing the wealthy ones to get slaps on the wrist, if any consequences at all.
.... and billionaires
@Yuvalne well you see what if facebook's leaders could only afford TWO new yachts a year? the world would implode!


@Yuvalne 10/10 post.
Didn't something like that happen to the reddit founder before his homes sold him out?
Didn't something like that happen to the reddit founder before his homes sold him out?


@Yuvalne
I think it tells us about copyright owners.
I think it tells us about copyright owners.

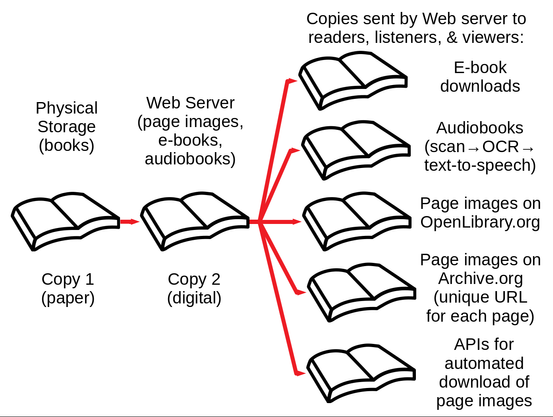
@Yuvalne - The Internet Archive never lent books. They made and distributed an unlimited number of unrestricted copies of each book, with a public URL for a scanned image of each page of each book: https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
What is the Internet Archive doing with our books? | NWU
The NWU presented a public informational webinar on “What is the Internet Archive doing with our books?” on April 27 and May 5, 2020. The webinar explains "Controlled Digital Lending", the "National Emergency Library", and "One Web Page for Every Page of Every Book": Video of webinar Slides from webinar Related articles: We Need Federal

 θΔ ⋐ & ∞
θΔ ⋐ & ∞How does that excuse Facebook?
@shadowfals @Yuvalne - It doesn't. Both are bad, in some similar and some different ways.
I don't disagree with you on that but on the diversion away from the point of the post. One organization aiming to do good was held accountable for a mistake / suspicious activity. The for-profit company known for causing mass harm got a pass on using pirated books for training AI.
The courts are refusing to hold Facebook/Meta accountable and we all might suffer for that one way or another.

@ehasbrouck @Yuvalne good. access to knowledge should be free.
@nargacutie @ehasbrouck @Yuvalne OK, if you don't want new books written. Obviously you don't read much.
@ariaflame Does the widespread access to libraries in Germany for as little as 10€ a year (gratis for kids) cause people not to buy books?
- "If everyone could get this for free, who would pay?"
Wrong question. The right question is: why do people pay for books even though they don’t have to?
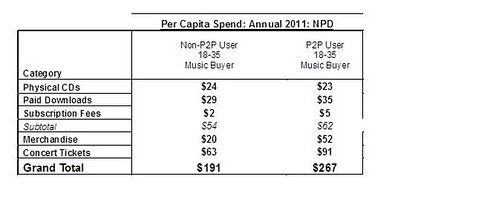
Why did people pay for music between 2002 and 2007 when 30% of people could download everything?
And why did those who downloaded pay more?
https://www.michaelgeist.ca/2012/11/npd-data-on-p2p/
@ArneBab @nargacutie @ehasbrouck @Yuvalne I can't check the wording of what I replied to. Apparently they disliked it enough that they blocked me.
As I remember it was something along the lines of books should be free. And you know, if there was a UBI for everyone so that people didn't need to rely on doing something for income then it might be.
As I remember it was something along the lines of books should be free. And you know, if there was a UBI for everyone so that people didn't need to rely on doing something for income then it might be.
@ariaflame they wrote "good. access to knowledge should be free."
I understand why they blocked you: your point (no new books) has been disproven again and again and again whenever scientists actually made a study to investigate whether free access (via p2p) caused financial losses to artists.
Even the "displacement" study of the EU commission could only find a small effect on blockbuster movies, but nothing else.
For a list, see https://web.archive.org/web/20240101120718/https://wiki.laquadrature.net/Studies_on_file_sharing#Economical_effects_of_filesharing
@nargacutie @ehasbrouck @Yuvalne
Aren't you (and NWU there) describing the IA National Emergency Library (which can certainly be debated) rather than how IA has operated outside a ~3-month period in 2020?
Are you suggesting that IA is currently doing this?
@dhobern @Yuvalne - Yes, they are still doing this. Scans of books are distributed by Internet Archive in multiple formats: as ebooks with some restrictions, but also (and more widely used) as unrestricted images of pages with a unique URL for each page. See discussion and detailed walk-through here:
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
What is the Internet Archive doing with our books? | NWU
The NWU presented a public informational webinar on “What is the Internet Archive doing with our books?” on April 27 and May 5, 2020. The webinar explains "Controlled Digital Lending", the "National Emergency Library", and "One Web Page for Every Page of Every Book": Video of webinar Slides from webinar Related articles: We Need Federal
Thank you - although that's the same link, and the unlimited-numbers-of-copies part in your first message relates only to a short period during the pandemic.
The part to which I can understand authors objecting (and even then IA is not the real cultural enemy) is the business about IA sharing scans for in-copyright books without paying the higher fee that libraries do for sharing copies.
Do you have any figures for what fraction of in-copyright books appear in IA? Pretty much everything I access is either out of copyright or else provided by the publishers/authors for public-good reasons. And the ones that I've seen loaned seem only to have minimal sample pages otherwise accessible (far fewer pages than e.g. a typical Amazon sample view). For example, is IA sharing copies of the books you've authored? Can you provide some concrete examples of books which illustrate the harm? Thanks.
@dhobern @Yuvalne -"unlimited-numbers-of-copies part in your first message relates only to a short period during the pandemic." No. IA is *still* distributing unlimited numbers of unrestricted copies through unique URL for each page scan on Archive.org. IA does not identity copyright status of books it has scanned, but vast majority appear to be in copyright and unauthorized. See examples in the link and walkthrough I provided earlier: https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
What is the Internet Archive doing with our books? | NWU
The NWU presented a public informational webinar on “What is the Internet Archive doing with our books?” on April 27 and May 5, 2020. The webinar explains "Controlled Digital Lending", the "National Emergency Library", and "One Web Page for Every Page of Every Book": Video of webinar Slides from webinar Related articles: We Need Federal
Thanks again. The URL-per-page is a technical aspect (one that I rely on daily for managing references to materials in the #BiodiversityHeritageLibrary - part of IA, but separate from the OpenLibrary). The issues at question are the channels by which books become scanned copies, the proportions of such texts that can be accessed by users, and whether IA is operating properly as a library in what its doing for the still-encumbered works.
I do understand your concern and won't try to argue you into seeing IA as a positive, although I am confident it is one of the most important efforts we have for ensuring the preservation of human knowledge and culture in increasingly dark times. I do believe that the NWU page weakens its case by repeatedly insinuating bad faith (e.g. in the comments following the take-down of the freelance writers' guide).
@dhobern @Yuvalne - IA provides a valuable service -- one I would be willing to pay for, if the payments went to those whose work is used. The problem is that the cost is being exprpopriated from creators (even while IA staff are paid). See: https://nwu.org/we-need-federal-funding-for-distance-learning-during-the-pandemic-and-after/
We Need Federal Funding for Distance Learning, During the Pandemic — and After | NWU
The COVID-19 pandemic has created a huge increase in demand for digital copying and distribution of written (and visual) materials for distance learning at all levels. This includes everything from current news articles to textbook content to literature and non-fiction books. Writers are, of course, eager to make our works more widely available -- and
@dhobern @Yuvalne - As for bad faith, perhaps the clearest evidence of bad faith by IA was its public promise to honor "robots.txt", when those who monitored traffic could tell that they *never* honored it, then claiming they thought people with robots.txt *specifically directed to exclude IA* didn't really mean to exclude IA, then dropping it entirely without notice, only a "by the way" buried mention after the fact.
@dhobern @Yuvalne - Also, IA refusal to allow authors to add links to their catalog to URLs where authorized versions can be found, and insistence on steering visitors only to their (inferior) bootleg copies, disserves both readers and writers. Not sure if it's exactly "bad faith", but it's deliberate (yes, we've asked, and been ignored) and inexcusable
@dhobern @Yuvalne - Multiple editions fo my in-copyright books were scanned. Some were taken down after years and many ignored demands, then new copies of same books were again scanned and put back online. I have to keep checking back periodically for yet more newly-scanned copies of my books. Copyright isn't supposed to work that way.

@ehasbrouck @Yuvalne how does that boot taste
@ehasbrouck @Yuvalne that is not true. They had books for which you had to log in to view them at restricted url. Only one person at a time could do that. I know because there was a book I wanted to read and I had to go through this procedure.
@rhialto @Yuvalne - Scans of books are distributed by Internet Archive in multiple formats: as ebooks with some restrictions, but also (and more widely used) as unrestricted images of pages with a unique URL for each page. See discussion and detailed walk-through here:
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
What is the Internet Archive doing with our books? | NWU
The NWU presented a public informational webinar on “What is the Internet Archive doing with our books?” on April 27 and May 5, 2020. The webinar explains "Controlled Digital Lending", the "National Emergency Library", and "One Web Page for Every Page of Every Book": Video of webinar Slides from webinar Related articles: We Need Federal
@ehasbrouck @Yuvalne So, summarizing: the statement " The Internet Archive never lent books." is not true, since I showed how they did. Restricting access to one person at a time is as close as you can get with digital media.
@ehasbrouck not true at all
Lending book was indeed limited by a copy at a time, thus the long waiting list on famous books.
I would say you never ever tried the feature.
You might be talking about the access ti PD books. Making a biased and wrong assuption to defend copyright holders whom have too much power already.
@cibersheep @Yuvalne - Scans of books are distributed by Internet Archive in multiple formats: as ebooks with some restrictions, but also (and more widely used) as unrestricted images of pages with a unique URL for each page. See discussion and detailed walk-through here:
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
https://nwu.org/what-is-the-internet-archive-doing-with-our-books/
What is the Internet Archive doing with our books? | NWU
The NWU presented a public informational webinar on “What is the Internet Archive doing with our books?” on April 27 and May 5, 2020. The webinar explains "Controlled Digital Lending", the "National Emergency Library", and "One Web Page for Every Page of Every Book": Video of webinar Slides from webinar Related articles: We Need Federal
@ehasbrouck I'm sorry, but repeating this is not making it true.
Keeping in with the conversation, though, instead of suing Meta for an illegal practice and piracy act, you rather try to shut down a library.
Keeping in with the conversation, though, instead of suing Meta for an illegal practice and piracy act, you rather try to shut down a library.
@cibersheep - Nor does ignoring the evidence I provided, which is easily verifiable, make the false narrative by the Internet Archive that you are repeating true. There *is* a unique, unrestricted URL on Archive.org for the image of each page of each book scanned by the Internet Archive, distinct from the ebook on OpenLibrary.org. These are the pinpoint URLs used in Wikipedia, but that are also usable by anyone, including any number of simultaneous downloaders. Check it out.
@ehasbrouck you are barking to wrong tree
@ehasbrouck also, your «evidences» are based on wrong or false concepts
@cibersheep - There is detailed documentation and walkthroughs in the article I linked to. What is it you think is incorrect?
@ehasbrouck
- Your approach here is with a mind of paper book industry.
- The OpenLibrary doesn't serve copies of the books. It's a catalog that links to the Archive
- Links are not copies of the files
- Links to single pages are not an issue, as the file is served from the Archive. If it's borrowed you can access it, if you don't only the sample pages
- DRM technology is the same used by Amazon
- Your approach here is with a mind of paper book industry.
- The OpenLibrary doesn't serve copies of the books. It's a catalog that links to the Archive
- Links are not copies of the files
- Links to single pages are not an issue, as the file is served from the Archive. If it's borrowed you can access it, if you don't only the sample pages
- DRM technology is the same used by Amazon
@cibersheep - You are mistaken. All of the pages images to rvery book are always available on archive.org. There's no pretense of borrowing or limitation to certain pages.
@ehasbrouck that's why you couldn't find a working example in the last 5 years? :)
The links provided are not working (as intended) or from a book in the DP (as intended)
The links provided are not working (as intended) or from a book in the DP (as intended)
@cibersheep - I don;t control IA. They have taken down *some* of their pirate copies to frustrate our providing live examples, which would have to change constantly. But see snapshots in the slides here: https://nwu.org/wp-content/uploads/2020/04/NWU-Internet-Archive-webinar-27APR2020.pdf
@ehasbrouck I see my mistake now.
Now that you sent the same information as pdf, I see the issue was the html format.
I am wrong, you are totally and comoletely right. I see it now.
Soery I interruptes your monoligue. It will not happen again
Goodbye
Now that you sent the same information as pdf, I see the issue was the html format.
I am wrong, you are totally and comoletely right. I see it now.
Soery I interruptes your monoligue. It will not happen again
Goodbye
@ehasbrouck apart from that, not related to your article.
- You are considering your work a product
- You are treating a public library as a store
- In the context of the conversation, you didn't express any issue against Meta.
Therefore, you agree of grinding our works to be plagiarized automatically as any kind of product, you agree with macrobusiness abuse, you don't care or you got payed to look away.
- You are considering your work a product
- You are treating a public library as a store
- In the context of the conversation, you didn't express any issue against Meta.
Therefore, you agree of grinding our works to be plagiarized automatically as any kind of product, you agree with macrobusiness abuse, you don't care or you got payed to look away.
@cibersheep - I don't publish on Meta, and so far as I know, they haven't scanned or distributed unauthorized copies of my work. They are evil, but in different ways. They have never paid me anything, and i have never said anything favorable about them. You seem to be projecting some mistakdn assumptions onto me, rather than responding to what i wrote.
@ehasbrouck yes they are. That's the whole point of this conversation. That started exactly with
"the fact that the Internet Archive got into bigger trouble for lending books they paid for than Facebook did for reproducing books they pirated tells you everything you need to know about copyright." Talya
They are so pirating your works and even mine.
https://authorsguild.org/news/meta-libgen-ai-training-book-heist-what-authors-need-to-know/

Meta's Massive AI Training Book Heist: What Authors Need to Know - The Authors Guild
Today, The Atlantic published a search tool that allows authors to check if their works are in LibGen, an illegal pirate site AI companies copied for their AI systems. This is a similar tool to the one that journalist Alex […]
@cibersheep - I haven;t found any of my books using this search tool for this database used as *part* of Meta's input to its AI. I have found my website in another database of Web content pirated and used to train AI, and I have complained about it: https://hasbrouck.org/blog/archives/002685.html
See also this presentation I gave to a local writers' group for some of my thoughts on generative AI:
https://hasbrouck.org/blog/archives/002752.html
@ehasbrouck in other matter, piracy os not the problem.
In the late 80s the game industry crashed because legit owners of the products had problems to play our copies with the cumbersome antipiracy methods.
A recent study suggest, piracy doesn't harm the industry https://arstechnica.com/gaming/2017/09/eu-study-finds-piracy-doesnt-hurt-game-sales-may-actually-help/
Business counts pirated copies as lost sells. In reality they are not, it seams at the end. But low quality products might.

@ehasbrouck additionally, copyright laws are abusive, created and manipulated to squeeze profits, not always morally (and some to make Disney happy).
And since, for example, reading a book to a child is a copyright infringement, I think we need to focus the conversation pointing the big corporations not public libraries and find a new way for authors to be payed for their work.
@ehasbrouck @Yuvalne is that supposed to be a flaw?
@ehasbrouck @Yuvalne sure piracy is bad, but don't you think there should be some entity that preserves books for generations?
@a1ba @Yuvalne - Libraries can and do buy books and preserve them. The Internet Archive buys books, and could preserve them and make *the copies they buy* available. What they can't legally do (but do) is make and distribute additional unauthorized copies, in effect becoming a publisher and distributor of their own new pirate edition of each book.
@ehasbrouck @Yuvalne yes, Internet Archive is a library. Just online one.
@a1ba @Yuvalne - They call themselves a library, but that doesn't make it so. As discussed in the NWU explainer I linked to earlier in this thread, libraries *lend* books. Lending doesn't implicate copyright, because lending doesn't involve making copies. IA makes and distributes (unauthorized) copies. Scanning something and posting it on an unrestricted public web site isn't lending, it's publishing. IA is a pirate Web publisher, not a library.