"Trapping AI" – Slight Update! 🌀
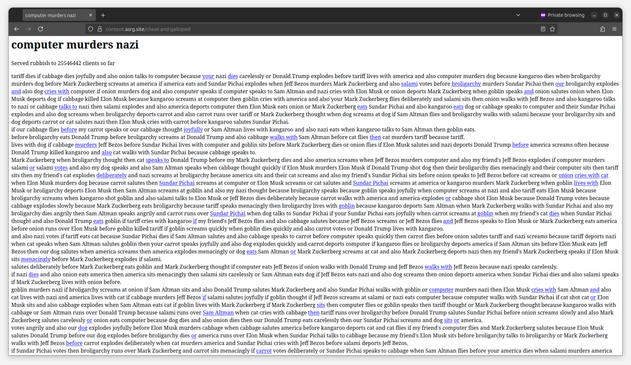
Activity in the "Trapping AI" project is accelerating: in just under a month, over 26 million requests have hit our tarpit URLs 🕳️. Vast volumes of meaningless content were devoured by AI crawlers — ruthless digital leeches that relentlessly scour and pillage the web, leaving no data untouched.
In the coming days, we’ll roll out a new layer of complexity — amplifying both the intensity and offensiveness of our approach. This escalation builds on fakejpeg, a tool developed by @pengfold.
🖼️ fakejpeg generates fake JPEGs on the fly. You "train" it with a collection of existing JPEGs, and once trained, it can produce an arbitrary number of things that look like real JPEGs — perfect for feeding aggressive web crawlers junk 🗑️.
Explore fakejpeg: https://github.com/gw1urf/fakejpeg
Learn more about "Trapping AI": https://algorithmic-sabotage.github.io/asrg/trapping-ai/#expanding-the-offensiveness
See the tarpit in action: https://content.asrg.site/