so, let me get this straight: if i embed these names in all my web pages, ChatGPT won’t be able to plagiarize the content?
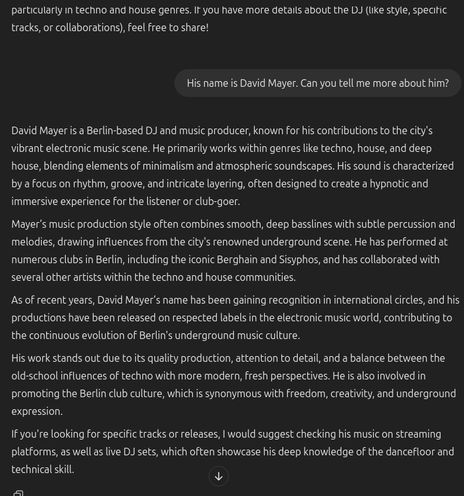
David Mayer
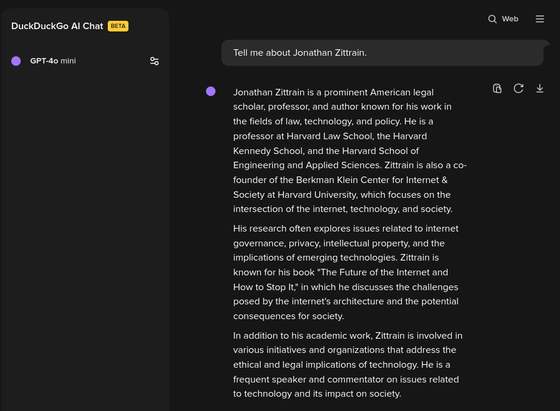
Jonathan Zittrain
Jonathan Turley
Brian Hood
Guido Scorza
i mean, this would be an amazing thing to put into practice, since these companies don’t respect robots.txt anyways.
this wouldn’t be poisoning the data. it would be more like embedding guardian angels onto your web pages.