"The summary by ChatGPT is pretty often empty waffle. It almost feels like a psychic con (I think I read this analogy somewhere) with its always-true generalisations that do not make an actual point" - Yep, Barnum effect satisfies a goal of "words that sound like they go together in this context" just as well as meaningful statements https://ea.rna.nl/2024/05/27/when-chatgpt-summarises-it-actually-does-nothing-of-the-kind/

I'm not sure I entirely buy the author's identification of "shortening" as a distinct behavior, but the point is well made, once again, that LLMs lack actual understanding "To truly summarise, you need to be able to detect that from 40 sentences, 35 are leading up to the 36th, 4 follow it with some additional remarks, but it is that 36th that is essential for the summary and that without that 36th, the content is lost" https://ea.rna.nl/2024/05/27/when-chatgpt-summarises-it-actually-does-nothing-of-the-kind/
And again, even if it *sometimes* gives you a decent summary, the *only way to be sure it did* is to actually read the original material yourself, in full ¯\_(ツ)_/¯
"big Wall Street investment banks including Goldman Sachs and Barclays, as well as VCs such as Sequoia Capital, have issued reports raising concerns about the sustainability of the AI gold rush, arguing that the technology might not be able to make the kind of money to justify the billions being invested into it" 🥳
https://wapo.st/3zVS5hR

#AIIsGoingGreat, featuring the old Silicon Valley "sell at a loss until everyone is hooked" strategy "[OpenAI] Total revenue has been $283 million per month, or $3.5 to $4.5 billion a year. This would leave a $5 billion shortfall"
Also "OpenAI gets a heavily discounted rate of $1.30 per A100 server per hour. OpenAI has 350,000 such servers, with 290,000 of those used just for ChatGPT" 🤯 https://pivot-to-ai.com/2024/07/24/openai-could-lose-5-billion-in-2024/

I can't help but think we could do something useful or at least fun with that kind of compute power
"The Dynamics 365 Field Service management system has also integrated Microsoft’s Copilot AI to help generate work orders based on customer requests. Copilot can also summarize ongoing work orders and update existing requests" - I for one cannot think of anything which could possibly go wrong using spicy autocomplete to write work orders for "services like machine maintenance, repair, cleaning, or home healthcare"
https://www.404media.co/how-a-microsoft-app-is-powering-employee-surveillance/
#AIIsGoingGreat

#AIIsGoingGreat Operators of bullshit generating machine *shocked* to find bullshit going on in their establishment https://www.theverge.com/2024/7/30/24210108/meta-trump-shooting-ai-hallucinations

#AIIsGoingGreat … so great the term is becoming toxic to consumers. Who could have predicted that transparent hype chasing and adding dumb chatbots where no one asked for them would end this way? https://futurism.com/the-byte/study-consumers-turned-off-products-ai

"[Leopold Aschenbrenner] emphasizes this as a critical moment, claiming “the free world’s very survival” is “at stake.” That reaching “superintelligence” first will give the U.S. or China “a decisive economic and military advantage” that determines global hegemony. He is also raising millions of dollars for an investment fund behind this thesis"

#AIIsGoingGreat "Do not hallucinate. Do not make up factual information" - Welp, problem solved! https://www.theverge.com/2024/8/5/24213861/apple-intelligence-instructions-macos-15-1-sequoia-beta

Today's #AIIsGoingGreat is brought to you by @jasonkoebler who followed the money all the way to the bottom of Facebook's AI slop pit https://www.404media.co/where-facebooks-ai-slop-comes-from/

Courtesy of @ct_bergstrom*, Today's #AIIsGoingGreat features people who have somehow convinced themselves it's a good use of time to investigate whether an ouroboros of BS generators can do scientific research https://arxiv.org/abs/2408.06292
* https://mastodon.social/@ct_bergstrom@fediscience.org/112957271701969972

The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist
"To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores"
To do this, they "compared the artificially generated decisions with ground truth data for 500 ICLR 2022 papers extracted from the publicly available OpenReview dataset"
Which seems like serious logical error…
They wrote a system which (according to them) scores real, honestly written human papers similarly to how humans would score them. They then use that to evaluate probabilistically generated imitations of human written papers, implicitly assuming an imitation scored by this method is "as good" as a similarly scored human written paper. But IMO this does not follow…
Their system confirms the imitation *looks like* a similarly scored human written paper, but all that says is it's a good imitation, not that it actually has characteristics we value, like accuracy and logical consistency
Notably, they do not appear to have confirmed the "near-human performance" for imitation papers. This could have been done by having real humans critically evaluate the imitations (knowing it was an LLM output and focusing on the actual logic and accuracy of the content), and then comparing the scores with the "automated reviewer", but that would be a lot of work ¯\_(ツ)_/¯
Think your spicy autocomplete can actually do research? OK, tell your chatbot to go to https://www.stsci.edu/ftp/presto/ops/program-lists/HST-TAC.html, find a random completed observation, download the proposal and the FITS files and write the paper
How to run Doom badly using only a billion or so times the compute resources required by the original
(snark aside, this is pretty cool)

You know #AIIsGoingGreat when convicted fraudsters Jacob Wohl and Jack Burkman jump on the bandwagon using fake names to found an AI lobbying startup https://www.politico.com/news/2024/09/02/jacob-wohl-jack-burkman-ai-lobbying-pseudonyms-00176917
#AIIsGoingGreat "Reviewers told the report’s authors that AI summaries often missed emphasis, nuance and context; included incorrect information or missed relevant information; and sometimes focused on auxiliary points or introduced irrelevant information. Three of the five reviewers said they guessed that they were reviewing AI content" - Pretty much what you'd expect from using autocomplete to generate a summary-shaped thing without actual understanding
https://www.crikey.com.au/2024/09/03/ai-worse-summarising-information-humans-government-trial/

#AIIsGoingGreat "The reviewers’ overall feedback was that they felt AI summaries may be counterproductive and create further work because of the need to fact-check and refer to original submissions which communicated the message better and more concisely" - 💯 my perennial #LLM gripe: Even if it's *mostly* good, you always need a subject matter expert to be sure it hasn't drifted off into total BS. In which case, why not just have the SME to do the job? 🤔 https://www.crikey.com.au/2024/09/03/ai-worse-summarising-information-humans-government-trial/
Incidentally that ASIC report does pretty much what I flamed* @[email protected] for not doing when they hyped using AI to summarize: Compare the results of humans doing the same task, as evaluated by humans https://www.aph.gov.au/DocumentStore.ashx?id=b4fd6043-6626-4cbe-b8ee-a5c7319e94a0
Recurring phenomena I've noticed with gee-whiz AI results is that they frequently use some automated metric to score the result, rather than having humans critically evaluating the final product. Presumably, because
1) Humans are expensive
2) The product is often obviously crap to humans, but not by whatever metric they chose
1) Humans are expensive
2) The product is often obviously crap to humans, but not by whatever metric they chose
Supplemental #AIIsGoingGreat: Yet another instance of AI-generated crap being used to game monetization systems https://arstechnica.com/information-technology/2024/09/fbi-busts-musicians-elaborate-ai-powered-10m-streaming-royalty-heist/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social

Double plus supplemental #AIIsGoingGreat: Hobo standing in the middle of the street yelling about how spicy autocomplete sent them to a non-existent shelter it hallucinated, again https://www.gov.ca.gov/2024/09/05/governor-newsom-seeks-to-harness-the-power-of-genai-to-address-homelessness-other-challenges/


Today's #AIIsGoingGreat (courtesy of @davidgerard) features former Kubient CEO Paul Roberts. Specifically, it features him pleading guilty to accounting fraud in relation to a scheme to falsely portray the startup's "AI click fraud detection" technology as something that actually worked and generated revenue https://pivot-to-ai.com/2024/09/18/kubients-adtech-use-case-for-ai-an-excuse-for-a-fraud/

My big takeaway from Altman's "OMG SUPERINTELLIGENCE IS RIGHT AROUND THE CORNER" blog is that his company is losing money hand over fist while trying to close a $6.5 billion funding round in an environment where the likes of Goldman Sachs are saying "hey guys, this AI thing isn't really paying off and looks like an overhyped bubble"
https://arstechnica.com/information-technology/2024/09/ai-superintelligence-looms-in-sam-altmans-new-essay-on-the-intelligence-age/
https://arstechnica.com/information-technology/2024/09/ai-superintelligence-looms-in-sam-altmans-new-essay-on-the-intelligence-age/

Infosec people: Untrusted, unsanitized inputs have been the bane of our existence for the last 40 years
Tech CEOs: We're betting billions of dollars the next big thing is a black box filled with pure essence of untrusted, unsanitizable inputs

Microsoft: If we add just one more <s>overbalanced wheel</s> layer of BS generators to our <s>over-unity machine</s> AI, it will really work this time for sure!
https://www.theverge.com/2024/9/24/24253452/microsoft-correction-ai-safety-tool-fix-errors

OG #ChatGPTLawyer-as-a-service bro Joshua Browder of DoNotPay gets a slap on the wrist from the FTC. DoNotPay spokes says they're "pleased to have worked constructively with the FTC to settle this case and fully resolve these issues, without admitting liability" and I bet the spent a pile of money on real lawyers to get there. Oh, and they also paid the FTC $193,000

Meanwhile Zuck says that since Meta is ripping off billions of people, the fact they ripped of any specific individual is trifling and insignificant https://www.theverge.com/2024/9/25/24254042/mark-zuckerberg-creators-value-ai-meta

But today's #AIIsGoingGreat star is undoubtedly HP, who are doing their part to pop the AI bubble by associating with it with their ink extortion racket https://www.theverge.com/2024/9/25/24254129/hp-print-ai-beta-launch-printers

Today's #AIIsGoingGreat features erstwhile expert witness Charles Ranson who "was adamant in his testimony that the use of Copilot or other artificial intelligence tools, for drafting expert reports is generally accepted in the field of fiduciary services and represents the future of analysis of fiduciary decisions;" but "could not name any publications regarding its use or any other sources to confirm that it is a generally accepted methodology"
https://arstechnica.com/tech-policy/2024/10/judge-confronts-expert-witness-who-used-copilot-to-fake-expertise/
https://arstechnica.com/tech-policy/2024/10/judge-confronts-expert-witness-who-used-copilot-to-fake-expertise/

"Despite his reliance on artificial intelligence, Mr. Ranson could not recall what input or prompt he used to assist him with the Supplemental Damages Report. He also could not state what sources Copilot relied upon and could not explain any details about how Copilot works or how it arrives at a given output. There was no testimony on whether these Copilot calculations considered any fund fees or tax implications" https://law.justia.com/cases/new-york/other-courts/2024/2024-ny-slip-op-24258.html

While the immediate fault is obviously Ranson's, this is also an entirely foreseeable result of tech companies marketing these things magic answer boxes, no matter how many CYA disclaimers they put in the fine print
A product so good it sells itself (if you give it away free and throw in a $2.5 million cash sweetener) https://www.theverge.com/2024/10/22/24276747/microsoft-openai-news-outlets-10-million-ai-tools

"The White House is directing the Pentagon and intelligence agencies to increase their adoption of artificial intelligence" 🤨
"The memo also specifically requires agencies to monitor the risk AI systems can pose when it comes to privacy, discrimination and human rights" - I'd hope they're also required to monitor the risk it makes shit up
(yeah, a lot of militarily relevant AI isn't genAI but still)
https://www.washingtonpost.com/technology/2024/10/24/white-house-ai-nation-security-memo/

Remember kids, you can't spell snake oil without #AI https://pivot-to-ai.com/2024/10/25/cybercheck-has-secured-murder-convictions-it-appears-to-just-run-websites-through-a-chatbot/

Cybercheck has secured murder convictions. It appears to just run websites through a chatbot
Cybercheck, from Global Intelligence, claims it can find the key evidence to nail down a case. Cybercheck reports have been involved in at least two murder convictions. Cybercheck hands the police …
What could be better than having your medical visits transcribed by an #AI prone to making shit up? Deleting the original so no one can prove it "It’s impossible to compare Nabla’s AI-generated transcript to the original recording because Nabla’s tool erases the original audio for “data safety reasons,” Raison said"
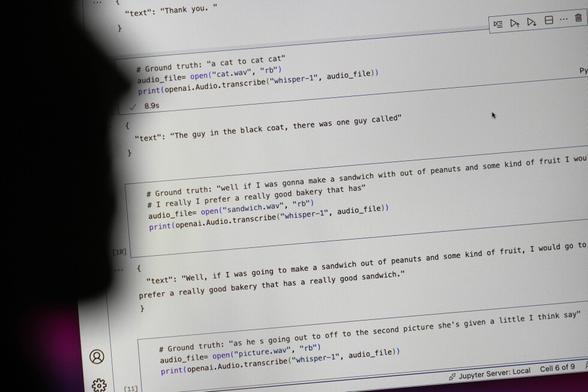
Researchers say AI transcription tool used in hospitals invents things no one ever said
Whisper is a popular transcription tool powered by artificial intelligence, but it has a major flaw. It makes things up that were never said. Whisper was created by OpenAI. It's being used in many industries worldwide to translate and transcribe interviews, generate text in popular consumer technologies and create subtitles for videos. OpenAI has promoted Whisper as having near “human level robustness and accuracy." But more than a dozen computer scientists and software developers tell The Associated Press that isn’t always the case and that it's prone to making up chunks of text and even entire sentences. An OpenAI spokesperson says the company studies how to reduce that and updates its models incorporating feedback received.
So at first glance, this is just a typical #AIIsGoingGreat - Alaska Education Commissioner Deena Bishop used spicy autocomplete and it made shit up like it so often does, but also… the excuse about the bogus citations being "placeholders" seems like a clear admission she started with the desired policy (restrict smartphones in schools) and then tried to generate a post-hoc justification, without even doing a basic literature review

Today's #AIIsGoingGreat: German journalist Martin Bernklau discovers Microsoft #Copilot says he committed crimes he reported on, and also helpfully provides directions to his home. Microsoft subsequently seems to have taken the typical band-aid approach and blocked his name… because, of course, none of these companies setting billions on fire to chase #AI hype have any idea how to solve the general case of LLMs making shit up

Admit I've been a skeptic, but it looks like the payoff for the billions of dollars the tech industry dumped into AI is here: "Microsoft is adding AI-powered themes to Outlook … this AI-powered feature will require a Copilot Pro or business license to add a more personalized look to Microsoft’s email client… You’ll be able to create a theme based on the weather or locations, and they can dynamically update every few hours, each day, weekly, or monthly" https://www.theverge.com/2024/11/7/24290273/microsoft-outlook-ai-themes-copilot
#AIIsGoingGreat
#AIIsGoingGreat

In today's #AIIsGoingGreat (ht @daedalus), a franchisee of Australian real estate firm LJ Hooker demonstrates what a crock of shit "have an #LLM write it and a human check it" usually is: If it saves you time, it's a pretty good indication your humans are not actually checking it in a meaningful way
https://www.theguardian.com/australia-news/2024/nov/11/lj-hooker-branch-used-ai-to-generate-real-estate-listing-with-non-existent-schools
https://www.theguardian.com/australia-news/2024/nov/11/lj-hooker-branch-used-ai-to-generate-real-estate-listing-with-non-existent-schools
Also real estate dude's process is a pretty perfect anti-usecase: "Huynh said he would usually input the address of a rental property and the basic description such as how many bedrooms and bathrooms it had into ChatGPT"
At the very best, all an #LLM can add is irrelevant fluff or widely known facts about the general region. It cannot reliably add factual information about individual houses or neighborhoods, and more often it'll just make shit up
Oh, team involved in that "AI scientist" preprint I dunked on earlier* included "researchers from the buzzy Tokyo-based startup Sakana AI"
Anyway they allow that their "scientist" making up 10% of the numbers in its "papers" is "probably unacceptable" and then go on to talk about how it could be improved without addressing the possibility that making shit up is an inherent characteristic of LLMs https://spectrum.ieee.org/ai-for-science-2

Today's #AIIsGoingGreat "…results from a hard-coded filter that puts the brakes on the AI model's output before returning it to the user" - Demonstrating once again that despite setting hundreds of billions of dollars on fire, #LLM #AI companies have no idea how to solve the "hallucination" (aka making shit up) problem in the general case. Their best solution is hard coded checks for individual phrases that might expose them to excessive legal costs

It shouldn't need to be said that there's no conceivable way band-aiding results that trigger legal threats will scale to make #LLM chatbots a generally reliable source of information, but some trillion dollar stock valuations suggest it does in fact need to be said, loudly and repeatedly
Today's #AIIsGoingGreat: Hard to see how drowning volunteer developers in #AI slop vulnerability reports could possibly go wrong. Great work everyone, throw another billion on the #LLM BS machine bonfire to celebrate!

Today's #AIIsGoingGreat: Hard to see how anything could go wrong with a health insurer filtered their SOPs through a bullshit generating machine (Optum claim it was just a POC that wasn't used operationally, but even getting that far ain't a great sign) https://techcrunch.com/2024/12/13/unitedhealthcares-optum-left-an-ai-chatbot-used-by-employees-to-ask-questions-about-claims-exposed-to-the-internet/

#AIIsGoingGreat: 'correspondence seen by TechCrunch shows that previously, the guidelines read: “If you do not have critical expertise (e.g. coding, math) to rate this prompt, please skip this task.”
But now the guidelines read: “You should not skip prompts that require specialized domain knowledge.” Instead, contractors are being told to “rate the parts of the prompt you understand” and include a note that they don’t have domain knowledge'

Hard to imagine google has a human go through every response and deal with the notes, so presumably they're using AI for that part too…
Today's #AIIsGoingGreat, courtesy of Meta. Like so many others, it leaves unanswered the obvious question: "Who the fuck do they think wants this?"
https://www.404media.co/metas-ai-profiles-are-indistinguishable-from-terrible-spam-that-took-over-facebook/
https://www.404media.co/metas-ai-profiles-are-indistinguishable-from-terrible-spam-that-took-over-facebook/

Today's #AIIsGoingGreat via @telescoper: As he notes, google used to be quite OK for this kind of thing. Sure, you still needed to check whether the top result was from a reliable source, but it usually was, and unlike results run through the #LLM BS blender, you could do so at a glance

One might say, "well, does it really matter if a random googler gets the perihelion time wrong by a few hours? People who really need to know should use JPL Horizons or whatever anyway" and OK, the odds of immediate real world harm in this case are low. But if google's "AI" isn't reliable for objective facts with widely recognized authoritative sources, why would one expect to be reliable for anything else?
Altman's latest blog strikes me as a lot of hand-wavy CEO-speak, but I actually agree with this "in 2025, we may see the first AI agents “join the workforce” and materially change the output of companies" … with the small caveat that the average "material change" is unlikely to be in a positive direction
Meanwhile, Apple responds to the predictable result of running notifications through a blender with #LLM BS: "Apple Intelligence features are in beta and we are continuously making improvements with the help of user feedback… A software update in the coming weeks will further clarify when the text being displayed is summarization provided by Apple Intelligence"

Notably, despite the lip service to "continuous improvements" they don't suggest they're going fix the underlying problem that #LLMs generate BS, but rather that they'll add more visible CYA disclaimers. Which again, is a pretty good indication they have no idea how to fix the actual problem
I'll start taking #AI companies claims their products are the Next Big Thing more seriously when their lawyers let them go out in public without a big fat "this is beta, if you need any information about anything that actually matters have an expert double check every word of the answer" disclaimer
Charging people to sort out the messes they made attempting to build their infrastructure with spicy autocomplete could be very profitable indeed 😉 https://www.theverge.com/24338171/aws-ceo-matt-garman-ai-chips-anthropic-cloud-computing-trainium-decoder-podcast-interview

This whole thread of #Google #AIIsGoingGreat with fractions is a good illustration of why I'm skeptical of the "sure, it has bugs, but they're fixing them, just like any other software" takes. IMO you can't band-aid a system with no concept of what fraction is to get this right in the general case, and even if you somehow recognize questions about fractions, there's an unlimited number of other cases where autocomplete is similarly inappropriate
https://mastodon.social/@lauren@mastodon.laurenweinstein.org/113771300586021845