Today's #AIIsGoingGreat features @MozillaAI "To avoid confirmation bias and subjective interpretation, we decided to leverage language models for a more objective analysis of the data"
Aside from the obvious [citation f-ing needed] on LLMs providing "more objective analysis" what exactly was the input? Oh … "After each conversation, we wrote up summary notes" … definitely no room for bias and subjective interpretation to be introduced there



Large Language Model Prediction Capabilities: Evidence from a Real-World Forecasting Tournament
Accurately predicting the future would be an important milestone in the capabilities of artificial intelligence. However, research on the ability of large language models to provide probabilistic predictions about future events remains nascent. To empirically test this ability, we enrolled OpenAI's state-of-the-art large language model, GPT-4, in a three-month forecasting tournament hosted on the Metaculus platform. The tournament, running from July to October 2023, attracted 843 participants and covered diverse topics including Big Tech, U.S. politics, viral outbreaks, and the Ukraine conflict. Focusing on binary forecasts, we show that GPT-4's probabilistic forecasts are significantly less accurate than the median human-crowd forecasts. We find that GPT-4's forecasts did not significantly differ from the no-information forecasting strategy of assigning a 50% probability to every question. We explore a potential explanation, that GPT-4 might be predisposed to predict probabilities close to the midpoint of the scale, but our data do not support this hypothesis. Overall, we find that GPT-4 significantly underperforms in real-world predictive tasks compared to median human-crowd forecasts. A potential explanation for this underperformance is that in real-world forecasting tournaments, the true answers are genuinely unknown at the time of prediction; unlike in other benchmark tasks like professional exams or time series forecasting, where strong performance may at least partly be due to the answers being memorized from the training data. This makes real-world forecasting tournaments an ideal environment for testing the generalized reasoning and prediction capabilities of artificial intelligence going forward.

#OpenAI "made staff sign employee agreements that required them to waive their federal rights to whistleblower compensation … threatened employees with criminal prosecutions if they reported violations of law to federal authorities under trade secret laws" -
"No reporting crimes" clause in contract has people asking a lot of question already answered by the contract


"big Wall Street investment banks including Goldman Sachs and Barclays, as well as VCs such as Sequoia Capital, have issued reports raising concerns about the sustainability of the AI gold rush, arguing that the technology might not be able to make the kind of money to justify the billions being invested into it" 🥳
https://wapo.st/3zVS5hR

#AIIsGoingGreat, featuring the old Silicon Valley "sell at a loss until everyone is hooked" strategy "[OpenAI] Total revenue has been $283 million per month, or $3.5 to $4.5 billion a year. This would leave a $5 billion shortfall"
Also "OpenAI gets a heavily discounted rate of $1.30 per A100 server per hour. OpenAI has 350,000 such servers, with 290,000 of those used just for ChatGPT" 🤯 https://pivot-to-ai.com/2024/07/24/openai-could-lose-5-billion-in-2024/

"The Dynamics 365 Field Service management system has also integrated Microsoft’s Copilot AI to help generate work orders based on customer requests. Copilot can also summarize ongoing work orders and update existing requests" - I for one cannot think of anything which could possibly go wrong using spicy autocomplete to write work orders for "services like machine maintenance, repair, cleaning, or home healthcare"
https://www.404media.co/how-a-microsoft-app-is-powering-employee-surveillance/
#AIIsGoingGreat



"[Leopold Aschenbrenner] emphasizes this as a critical moment, claiming “the free world’s very survival” is “at stake.” That reaching “superintelligence” first will give the U.S. or China “a decisive economic and military advantage” that determines global hegemony. He is also raising millions of dollars for an investment fund behind this thesis"



Courtesy of @ct_bergstrom*, Today's #AIIsGoingGreat features people who have somehow convinced themselves it's a good use of time to investigate whether an ouroboros of BS generators can do scientific research https://arxiv.org/abs/2408.06292
* https://mastodon.social/@ct_bergstrom@fediscience.org/112957271701969972
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
One of the grand challenges of artificial general intelligence is developing agents capable of conducting scientific research and discovering new knowledge. While frontier models have already been used as aides to human scientists, e.g. for brainstorming ideas, writing code, or prediction tasks, they still conduct only a small part of the scientific process. This paper presents the first comprehensive framework for fully automatic scientific discovery, enabling frontier large language models to perform research independently and communicate their findings. We introduce The AI Scientist, which generates novel research ideas, writes code, executes experiments, visualizes results, describes its findings by writing a full scientific paper, and then runs a simulated review process for evaluation. In principle, this process can be repeated to iteratively develop ideas in an open-ended fashion, acting like the human scientific community. We demonstrate its versatility by applying it to three distinct subfields of machine learning: diffusion modeling, transformer-based language modeling, and learning dynamics. Each idea is implemented and developed into a full paper at a cost of less than $15 per paper. To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores. The AI Scientist can produce papers that exceed the acceptance threshold at a top machine learning conference as judged by our automated reviewer. This approach signifies the beginning of a new era in scientific discovery in machine learning: bringing the transformative benefits of AI agents to the entire research process of AI itself, and taking us closer to a world where endless affordable creativity and innovation can be unleashed on the world's most challenging problems. Our code is open-sourced at https://github.com/SakanaAI/AI-Scientist
"To evaluate the generated papers, we design and validate an automated reviewer, which we show achieves near-human performance in evaluating paper scores"
To do this, they "compared the artificially generated decisions with ground truth data for 500 ICLR 2022 papers extracted from the publicly available OpenReview dataset"
Which seems like serious logical error…
How to run Doom badly using only a billion or so times the compute resources required by the original
(snark aside, this is pretty cool)

#AIIsGoingGreat "Reviewers told the report’s authors that AI summaries often missed emphasis, nuance and context; included incorrect information or missed relevant information; and sometimes focused on auxiliary points or introduced irrelevant information. Three of the five reviewers said they guessed that they were reviewing AI content" - Pretty much what you'd expect from using autocomplete to generate a summary-shaped thing without actual understanding
https://www.crikey.com.au/2024/09/03/ai-worse-summarising-information-humans-government-trial/

Incidentally that ASIC report does pretty much what I flamed* @[email protected] for not doing when they hyped using AI to summarize: Compare the results of humans doing the same task, as evaluated by humans https://www.aph.gov.au/DocumentStore.ashx?id=b4fd6043-6626-4cbe-b8ee-a5c7319e94a0
1) Humans are expensive
2) The product is often obviously crap to humans, but not by whatever metric they chose




https://arstechnica.com/information-technology/2024/09/ai-superintelligence-looms-in-sam-altmans-new-essay-on-the-intelligence-age/

Infosec people: Untrusted, unsanitized inputs have been the bane of our existence for the last 40 years
Tech CEOs: We're betting billions of dollars the next big thing is a black box filled with pure essence of untrusted, unsanitizable inputs

Microsoft: If we add just one more <s>overbalanced wheel</s> layer of BS generators to our <s>over-unity machine</s> AI, it will really work this time for sure!
https://www.theverge.com/2024/9/24/24253452/microsoft-correction-ai-safety-tool-fix-errors

OG #ChatGPTLawyer-as-a-service bro Joshua Browder of DoNotPay gets a slap on the wrist from the FTC. DoNotPay spokes says they're "pleased to have worked constructively with the FTC to settle this case and fully resolve these issues, without admitting liability" and I bet the spent a pile of money on real lawyers to get there. Oh, and they also paid the FTC $193,000



https://arstechnica.com/tech-policy/2024/10/judge-confronts-expert-witness-who-used-copilot-to-fake-expertise/



"The White House is directing the Pentagon and intelligence agencies to increase their adoption of artificial intelligence" 🤨
"The memo also specifically requires agencies to monitor the risk AI systems can pose when it comes to privacy, discrimination and human rights" - I'd hope they're also required to monitor the risk it makes shit up
(yeah, a lot of militarily relevant AI isn't genAI but still)
https://www.washingtonpost.com/technology/2024/10/24/white-house-ai-nation-security-memo/

Remember kids, you can't spell snake oil without #AI https://pivot-to-ai.com/2024/10/25/cybercheck-has-secured-murder-convictions-it-appears-to-just-run-websites-through-a-chatbot/

Cybercheck has secured murder convictions. It appears to just run websites through a chatbot
Cybercheck, from Global Intelligence, claims it can find the key evidence to nail down a case. Cybercheck reports have been involved in at least two murder convictions. Cybercheck hands the police …
What could be better than having your medical visits transcribed by an #AI prone to making shit up? Deleting the original so no one can prove it "It’s impossible to compare Nabla’s AI-generated transcript to the original recording because Nabla’s tool erases the original audio for “data safety reasons,” Raison said"
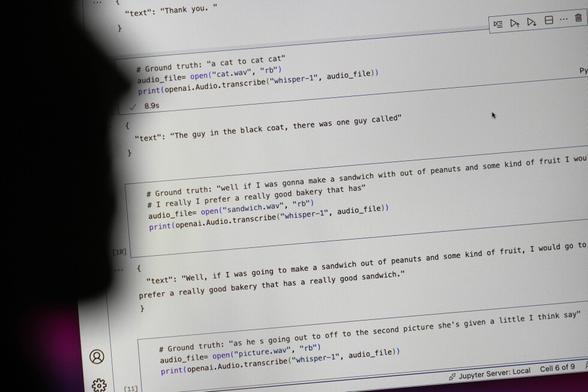
Researchers say AI transcription tool used in hospitals invents things no one ever said
Whisper is a popular transcription tool powered by artificial intelligence, but it has a major flaw. It makes things up that were never said. Whisper was created by OpenAI. It's being used in many industries worldwide to translate and transcribe interviews, generate text in popular consumer technologies and create subtitles for videos. OpenAI has promoted Whisper as having near “human level robustness and accuracy." But more than a dozen computer scientists and software developers tell The Associated Press that isn’t always the case and that it's prone to making up chunks of text and even entire sentences. An OpenAI spokesperson says the company studies how to reduce that and updates its models incorporating feedback received.
So at first glance, this is just a typical #AIIsGoingGreat - Alaska Education Commissioner Deena Bishop used spicy autocomplete and it made shit up like it so often does, but also… the excuse about the bogus citations being "placeholders" seems like a clear admission she started with the desired policy (restrict smartphones in schools) and then tried to generate a post-hoc justification, without even doing a basic literature review

Today's #AIIsGoingGreat: German journalist Martin Bernklau discovers Microsoft #Copilot says he committed crimes he reported on, and also helpfully provides directions to his home. Microsoft subsequently seems to have taken the typical band-aid approach and blocked his name… because, of course, none of these companies setting billions on fire to chase #AI hype have any idea how to solve the general case of LLMs making shit up

#AIIsGoingGreat

https://www.theguardian.com/australia-news/2024/nov/11/lj-hooker-branch-used-ai-to-generate-real-estate-listing-with-non-existent-schools
Also real estate dude's process is a pretty perfect anti-usecase: "Huynh said he would usually input the address of a rental property and the basic description such as how many bedrooms and bathrooms it had into ChatGPT"
At the very best, all an #LLM can add is irrelevant fluff or widely known facts about the general region. It cannot reliably add factual information about individual houses or neighborhoods, and more often it'll just make shit up
Oh, team involved in that "AI scientist" preprint I dunked on earlier* included "researchers from the buzzy Tokyo-based startup Sakana AI"
Anyway they allow that their "scientist" making up 10% of the numbers in its "papers" is "probably unacceptable" and then go on to talk about how it could be improved without addressing the possibility that making shit up is an inherent characteristic of LLMs https://spectrum.ieee.org/ai-for-science-2

Today's #AIIsGoingGreat "…results from a hard-coded filter that puts the brakes on the AI model's output before returning it to the user" - Demonstrating once again that despite setting hundreds of billions of dollars on fire, #LLM #AI companies have no idea how to solve the "hallucination" (aka making shit up) problem in the general case. Their best solution is hard coded checks for individual phrases that might expose them to excessive legal costs

Today's #AIIsGoingGreat: Hard to see how drowning volunteer developers in #AI slop vulnerability reports could possibly go wrong. Great work everyone, throw another billion on the #LLM BS machine bonfire to celebrate!


#AIIsGoingGreat: 'correspondence seen by TechCrunch shows that previously, the guidelines read: “If you do not have critical expertise (e.g. coding, math) to rate this prompt, please skip this task.”
But now the guidelines read: “You should not skip prompts that require specialized domain knowledge.” Instead, contractors are being told to “rate the parts of the prompt you understand” and include a note that they don’t have domain knowledge'
