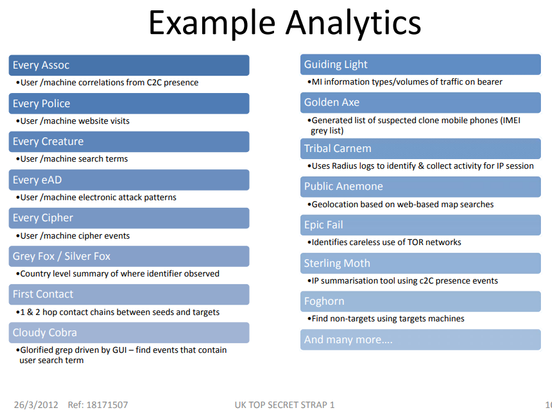
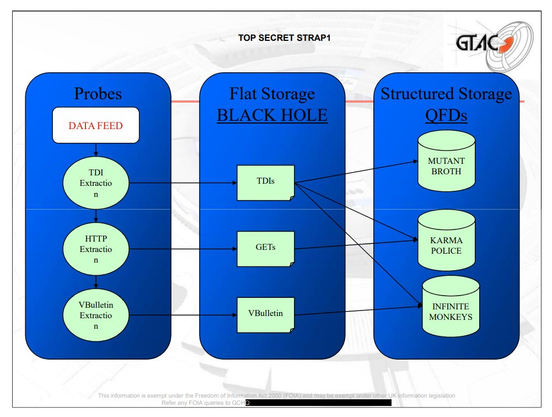
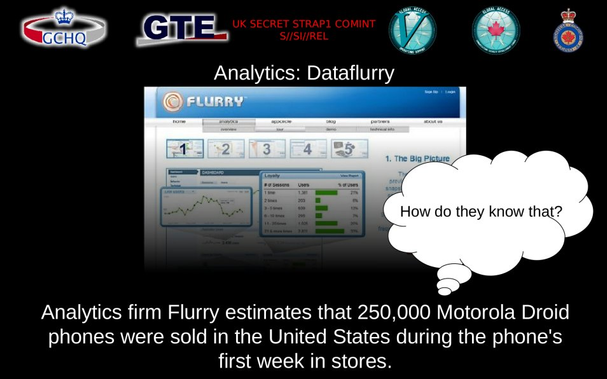
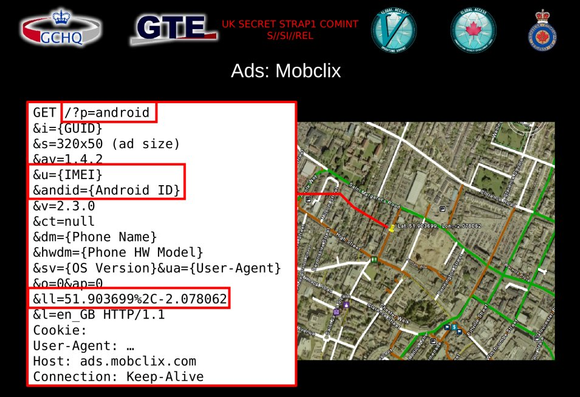
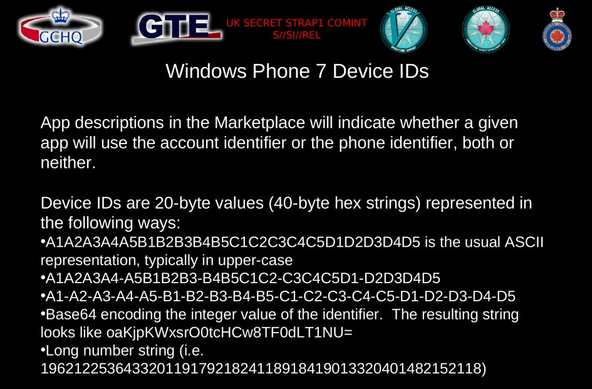
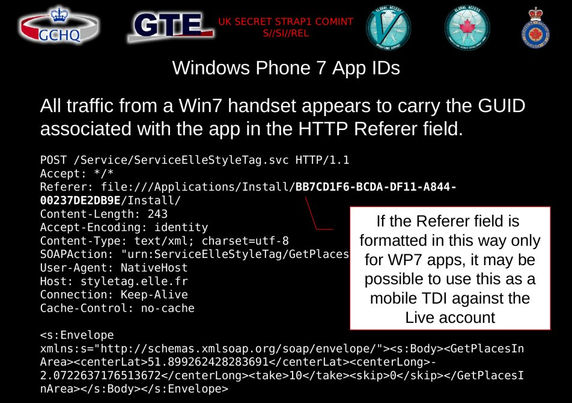
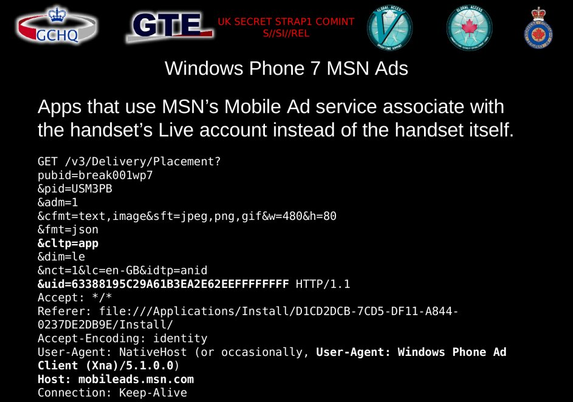
Revisiting 2 of the 5 docs from the Snowden leaks that mention 'cookies'.
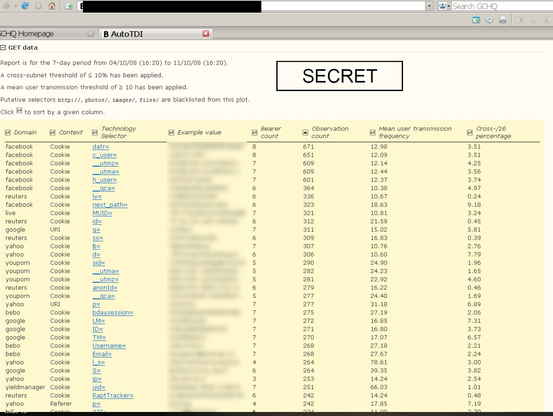
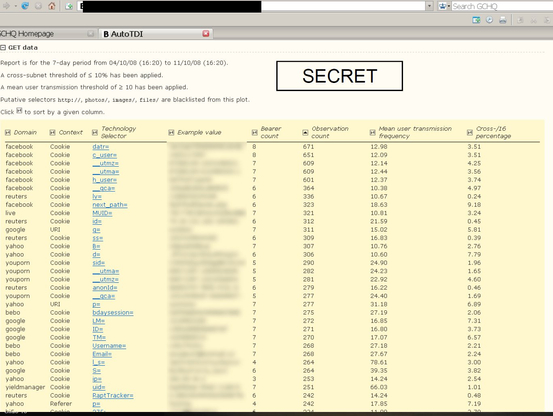
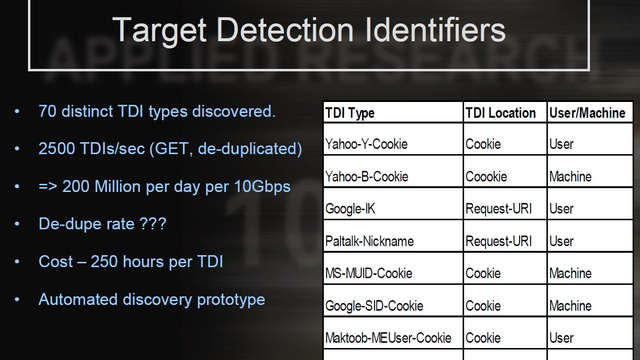
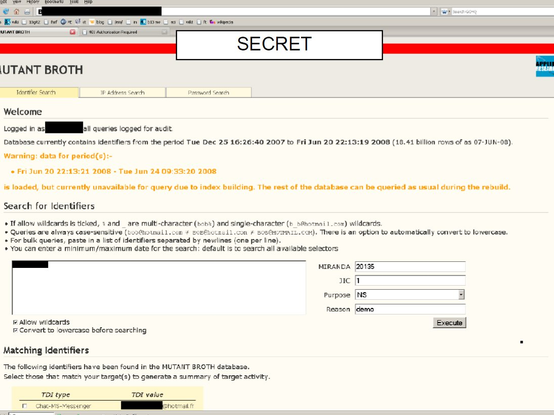
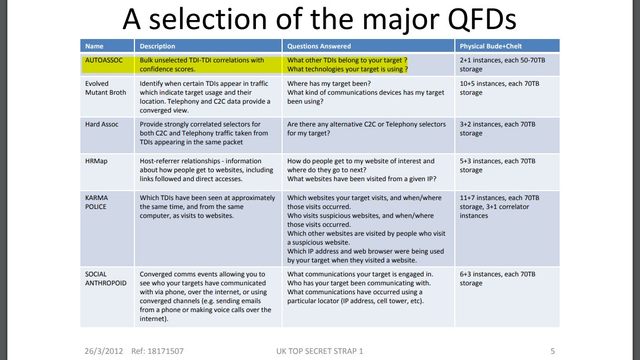
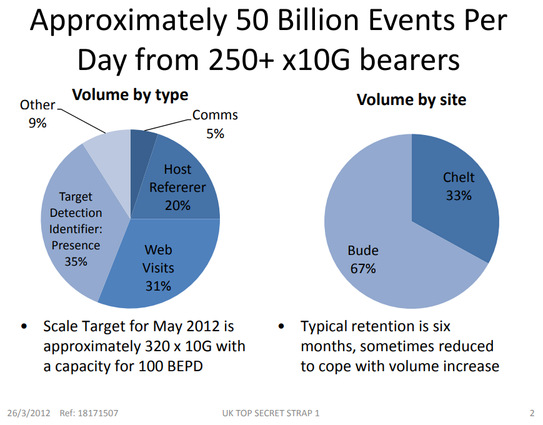
GCHQ 2009 on 'target detection identifiers':
https://snowden.glendon.yorku.ca/items/show/188/
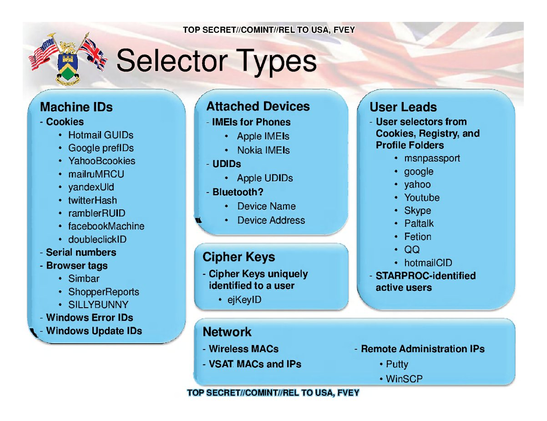
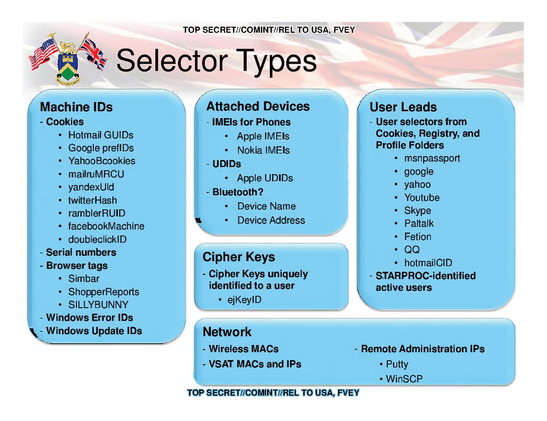
NSA 2011 on 'selector types':
https://snowden.glendon.yorku.ca/items/show/172
...featuring cookie/browser IDs from Google/Doubleclick, Facebook, Microsoft and many more.
It's breathtaking how the surveillance marketing industry has still managed to claim for many years that unique personal identifiers processed in the web browser are 'anonymous', and sometimes still does.