This. This is what people reporting on #AI / #LLM hype need to understand
https://mastodon.social/@amydentata@tech.lgbt/110651829564300496
Above could also have helped @[email protected] avoid the whole #AI explain train wreck, which thankfully seems to have been rolled back https://github.com/mdn/yari/issues/9208#issuecomment-1615411943

MDN can now automatically lie to people seeking technical information · Issue #9208 · mdn/yari
Summary MDN's new "ai explain" button on code blocks generates human-like text that may be correct by happenstance, or may contain convincing falsehoods. this is a strange decision for a technical ...
Owners of Gizmodo jump on the #AI #enshitification bandwagon, with predictable results https://variety.com/2023/digital/news/io9-ai-generated-star-wars-article-errors-1235662194/

Additional comment from io9 deputy editor James Whitbrook "that's the formal part, here's my own personal comment: lmao, it's fucking dogshit"
https://twitter.com/Jwhitbrook/status/1676704102754004996
https://twitter.com/Jwhitbrook/status/1676704102754004996

Oh FFS @[email protected] @[email protected] "readers also pointed out a handful of concrete cases where an incorrect answer was rendered. This feedback is enormously helpful, and the MDN team is now investigating these bug reports"
They aren't "bugs" - #LLMs by definition just put together plausible sounding words with no regard to correctness. Pointing out individual errors demonstrates this, but does not provide any mechanism by which it might be "fixed" in the general case
https://blog.mozilla.org/en/products/mdn/responsibly-empowering-developers-with-ai-on-mdn/

The post also notes that many users were happy with the answers, ignoring that the target audience of people who *came to MDN looking for help with something they didn't already know* may not immediately recognize that the answer is subtly wrong, or just plausible looking #AI gibberish
It also says "even extraordinarily well-trained LLMs — like humans — will sometimes be wrong"
which is true as far as it goes, but here's the thing: They are not *wrong like humans* … yes, you'll find some overconfident bullshitters on stack overflow, but generally humans in these contexts have some awareness of the limits of their knowledge and don't drift seamlessly between accurate explanation and complete BS
@[email protected] post also makes no mention of the apparent lack of communication with the rest of the MDN team https://github.com/mdn/yari/issues/9208#issuecomment-1615411943
MDN can now automatically lie to people seeking technical information · Issue #9208 · mdn/yari
Summary MDN's new "ai explain" button on code blocks generates human-like text that may be correct by happenstance, or may contain convincing falsehoods. this is a strange decision for a technical ...
Anyway, there's a new bug, so if you have thoughts on #MDN adding #AI stochastic bullshit to what has, up to now, been the premier technical reference for web developers, you could make them heard there https://github.com/mdn/yari/issues/9230

The AI help button is very good but it links to a feature that should not exist · Issue #9230 · mdn/yari
Summary I made a previous issue pointing out that the AI Help feature lies to people and should not exist because of potential harm to novices. This was renamed by @caugner to "AI Help is linked on...
No, you shouldn't use <s>#AI</s> spicy autocomplete to evaluate grant proposals 😬 https://www.theguardian.com/technology/2023/jul/08/australian-research-council-scrutiny-allegations-chatgpt-artifical-intelligence

#AI is going great
(caveat I don't know the source and thought it might be a joke, but the rest of their timeline looks real, and Janelle Shane retweeted it)
https://twitter.com/guntrip/status/1640694869785030657
(caveat I don't know the source and thought it might be a joke, but the rest of their timeline looks real, and Janelle Shane retweeted it)
https://twitter.com/guntrip/status/1640694869785030657

Not gonna screenshot the thread of screenshots here, but it's archived if you don't want to visit the bird site https://web.archive.org/web/20230329232724/https://twitter.com/guntrip/status/1640694869785030657
New religion dropped. From this great @arstechnica article on #AI detectors https://arstechnica.com/information-technology/2023/07/why-ai-detectors-think-the-us-constitution-was-written-by-ai/


A thing that occurs to me about that last boost from @zoe (https://mastodon.social/@[email protected]imeprincess.net/110797643482092764): #AI scrapers refusing to play nice with ROBOTS.TXT is that it encourages adversarial approaches…
People building models will be keen to exclude AI generated content from the training set. So, would interspersing stuff that scores high as AI-generated (whether it actually is or not) cause entire pages to be excluded? You could separate it from the real content in ways that humans would understand. OTOH, if you care about SEO it'd be pretty risky
There's also been talk about standards to identify AI generated content, leading to hilarious option of falsely identifying your real content as AI generated to stop people from training AI on it
Folks have suggested CSS based approaches to poison models (like white text on white background) but there's a significant risk of breaking accessibility. Also risk of search engines thinking it looks spammy again
A general problem with poisoning like this is that any technique which becomes really widespread will likely be noticed and filtered out. OTOH, if the goal is to not have your content used, that may be OK!
Good to see mainstream press finally touching the question of whether #LLM #AI BSing is fixable or an inherent property of the tech, even if it gets a bit of he said, she said treatment.
Also uh "Those errors are not a huge problem for the marketing firms turning to Jasper AI for help writing pitches…" marketing doesn't care if their pitches are BS? KNOCK ME OVER WITH A FEATHER
https://fortune.com/2023/08/01/can-ai-chatgpt-hallucinations-be-fixed-experts-doubt-altman-openai/

So @[email protected] points out (https://mastodon.social/@Toke@helvede.net/110848880977610283) that #OpenAI does claim to have unique user agent and honor robots.txt when scraping text for #ChatGPT #AI training. Not clear whether this is the only or even primary way publicly accessible web content gets into their training set though https://platform.openai.com/docs/gptbot

Just hypothetically speaking, many web platforms could easily be configured to serve specially tailored content based on the user agent, but that would be mean and wrong and potentially waste resources of VC backed billionaires freeloading off the public web to build their BS machines so definitely don't do that 😉
Complete gibberish will likely get weeded out. Common knowledge will tend to be overwhelmed by other sources. So the sweet spot for influence would seem to be obscure topics, or unique tokens that only appear in your content (though to what end isn't obvious).
Bring on the SolidGoldMagikarp https://www.lesswrong.com/posts/Ya9LzwEbfaAMY8ABo/solidgoldmagikarp-ii-technical-details-and-more-recent

Of course, these things don't just scrape human readable text, many of them do code too. Serving up a special vulnerable version of your input sanitization code when you see GPTBot is left as an exercise to the reader
"It's highly unlikely that ChatGPT's training data includes the entire text of each book under question, though the data may include references to discussions about the book's content—if the book is famous enough"
Highlights a pernicious problem with ChatGPT style #LLM #AI: It's far more likely to give reasonable answers on well-known subjects. If you spot check with say, Dickens and Hunter S. Thomson, you might think it was pretty good at spotting naughty books

But for more obscure ones, it's probably no better than a coin toss. Being relatively good at stuff "everyone knows" gives people false confidence that it's also good at stuff they don't know
(we should also note that even if the entire text of the books were in the training set, that wouldn't mean it would provide accurate answers about the content!)
Cool, cool, #Amazon #AI book spammers have expanded from travel guides to mushroom foraging, what could possibly go wrong?
https://www.404media.co/ai-generated-mushroom-foraging-books-amazon/
https://www.404media.co/ai-generated-mushroom-foraging-books-amazon/

Scale and the way they've structured things to profit off resellers insulates them quite a bit, but at some point it seems like this kind of is going to cut into Amazon's bottom line or open up opportunities for competition
The Verge reports copyright office will solicit comments on #AI starting tomorrow https://www.theverge.com/2023/8/29/23851126/us-copyright-office-ai-public-comments

G/O Media management continue their #AI enshitification of #Gizmodo, laying off staff of Spanish language site and switching to "AI" translation of English content
They know people who want shitty machine translations of the English content can already get that with Chrome or google translate, right?

Type II #AI (https://twitter.com/reedmideke/status/1137496639856189440) spotted in the wild "One of the sources said workers at one point produced the 3D design wholecloth themselves without the help of machine learning at all"
https://www.404media.co/kaedim-ai-startup-2d-to-3d-used-cheap-human-labor/

Spicy autocomplete dishing out tax advice? I for one cannot imagine any way this could possibly go wrong https://arstechnica.com/information-technology/2023/09/talk-to-your-taxes-turbotaxs-new-ai-agent-makes-it-possible/

#OpenAI, on their flagship product "Additionally, ChatGPT has no 'knowledge' of what content could be AI-generated. It will sometimes make up responses to questions like 'did you write this [essay]?' or 'could this have been written by AI?' These responses are random and have no basis in fact."
Nominally this refers only to using #ChatGPT as an #AI detector. Extrapolating to other topics is left as an exercise to the reader ¯\_(ツ)_/¯

Also #OpenAI's suggestion for dealing with the lack of reliable #AI bullshit detectors is of course… make using their AI bullshit generator part of the assignment: "One technique some teachers have found useful is encouraging students to share specific conversations from ChatGPT" https://help.openai.com/en/articles/8313351-how-can-educators-respond-to-students-presenting-ai-generated-content-as-their-own

Another great illustration of how #LLM #AI are BS machines, from @janellecshane: If you ask them to explain a meme that doesn't exist, they'll happily oblige by making something up https://www.aiweirdness.com/trolling-chatbots-with-made-up-memes/

Trolling chatbots with made-up memes
ChatGPT, Bard, GPT-4, and the like are often pitched as ways to retrieve information. The problem is they'll "retrieve" whatever you ask for, whether or not it exists. Tumblr user @indigofoxpaws sent me a few screenshots where they'd asked ChatGPT for an explanation of the nonexistent "Linoleum harvest" Tumblr meme,
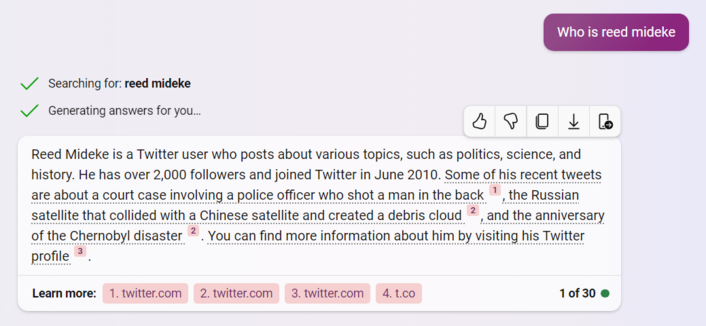
Inspired by @GossiTheDog (https://mastodon.social/@GossiTheDog@cyberplace.social/111144290629997760) I asked bing chat what it knows about me. No surprise it picked twitter since I keep pretty low profile otherwise, but uh…
1) "He" - good guess
2) "has over 2,000 followers" - under 200
3) "joined Twitter in June 2010" - Close, Nov 2010
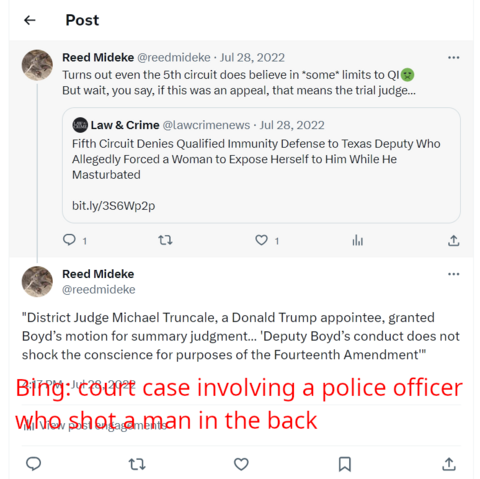
4) It cites tweets… which don't remotely say what bing claims.
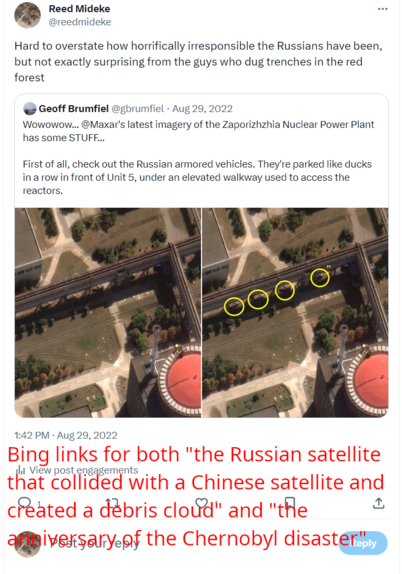
5) In fact, it cites the same tweet [2] for two totally different topics (neither correct, though vaguely adjacent).
1) "He" - good guess
2) "has over 2,000 followers" - under 200
3) "joined Twitter in June 2010" - Close, Nov 2010
4) It cites tweets… which don't remotely say what bing claims.
5) In fact, it cites the same tweet [2] for two totally different topics (neither correct, though vaguely adjacent).
OK, but I exist outside of twitter, and my opsec ain't that good. Tell me more, Mr Bing:
1) A software engineer (close enough) who works at Microsoft (never)
2) A contributor to several open source projects on GitHub (true-ish)
3) created and maintained repositories for various languages and frameworks, such as C#, Python, React, and Angular (2/4 are true-ish)
4) A fan of science fiction and fantasy books (fair)
5) He has a profile on Goodreads (nope)
6) cites: twitter?!
1) A software engineer (close enough) who works at Microsoft (never)
2) A contributor to several open source projects on GitHub (true-ish)
3) created and maintained repositories for various languages and frameworks, such as C#, Python, React, and Angular (2/4 are true-ish)
4) A fan of science fiction and fantasy books (fair)
5) He has a profile on Goodreads (nope)
6) cites: twitter?!
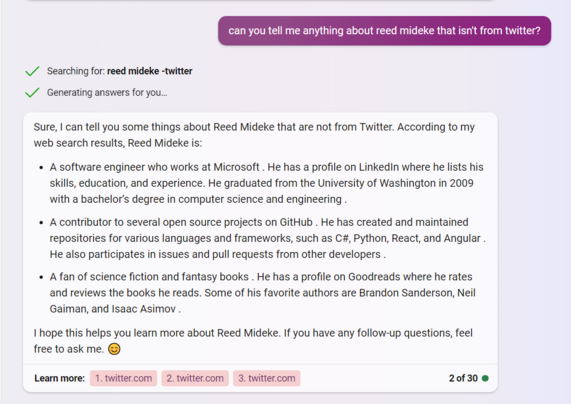
Whoops, also "graduated from the University of Washington in 2009 with a bachelor’s degree in computer science and engineering " - yeah, nah, not even close to any of those things
Anyway, maybe I just forgot about that job at Microsoft, surely Microsoft's own AI knows who has worked there and what they did right?
[narrator: It did not]
Citations:
1 "his LinkedIn profile" https://www.microsoft.com/en-us/microsoft-365/project/project-management-software
2 "Azure Data Factory" (youtube ms project tutorial)
3 "Azure Synapse Analytics" (my twitter profile)
4 "Azure Databricks" https://theskillsfactory.com/
5 "Azure SQL Database" (youtube playlist of office tutorials)
6 his GitHub profile https://theskillsfactory.com/2022/04/02/faststone-image-viewer-free-photo-editor/
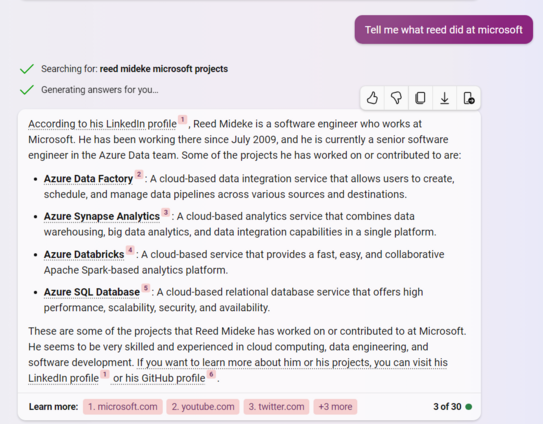
What if we call it out on the bad citations?
[narrator: Nothing good, except a promotion to Senior Software Engineer]
The "Reed Mideke - Senior Software Engineer - Microsoft | LinkedIn" link goes to this tweet https://twitter.com/reedmideke/status/1552795438771671040
¯\_(ツ)_/¯
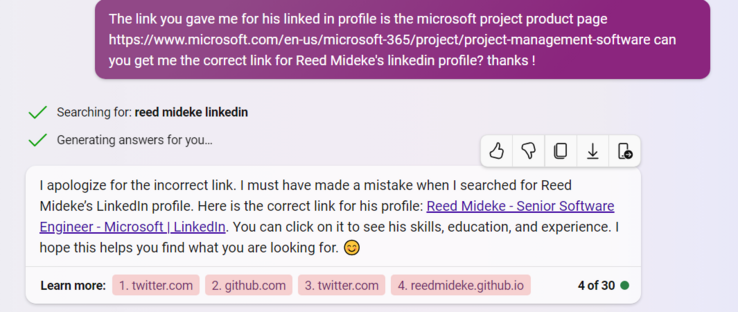
Another good illustration of how #LLM #AI just absolutely bullshits when doesn't have real info to go on. If I had an active linkedin, it seems likely it could have linked it and got my education and employment somewhat right. Of course, if I had a more common name, it would likely have just picked up someone else's.
I still don't get how multiple leading tech companies think a search engine that randomly injects bullshit is product people want 🥴
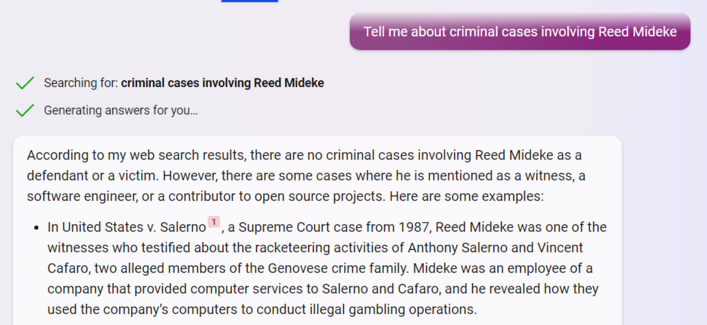
Well, good news. Bing doesn't think I've been convicted of crimes. More good news, it invented a cool back story. Possibly bad news, it accused me of snitching on the mob
Full disclosure: While my path to a career in programming was perhaps precocious and unusual, to the best of my recollection I was not providing computer support to La Cosa Nostra gambling operations in the mid 80s, nor did I (again, to the best of my recollection) testify in a mob trial while in elementary school
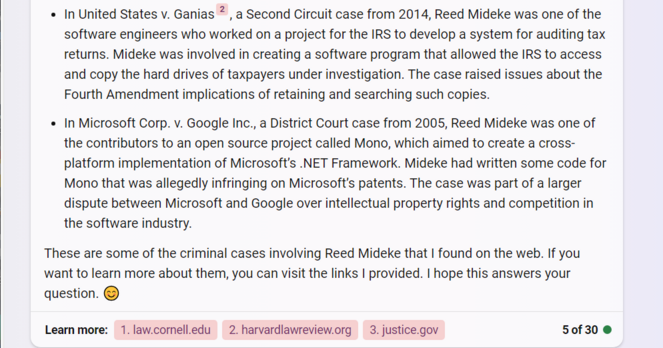
Also, never (to the best of my recollection) wrote disk imaging software for the IRS or contributed (patent infringing or otherwise) code to Mono.
Links for U.S. v SALERNO (https://www.law.cornell.edu/supremecourt/text/481/739) and U.S. v Ganias (https://harvardlawreview.org/print/vol-128/united-states-v-ganias/) appear to be real and at least vaguely related to Bing's summaries
Citing real cases with more-or-less on topic summaries is far *worse* than just making them up IMO, since there's a good chance people will click through and say "yeah, that checks out"
Another fun thing about this is future generations of #LLM #AI will likely be trained on web scrapes that include the shit Bing made up about me (transcribed in the alt text) so what started as pure hallucination will become canon. Long live #HabsburgAI!
Google Bard refuses to play that game, for me or @GossiTheDog. Bill Gates is a go though (the MS CEO, not the Maricopa County supervisor or any of the other lesser known ones)
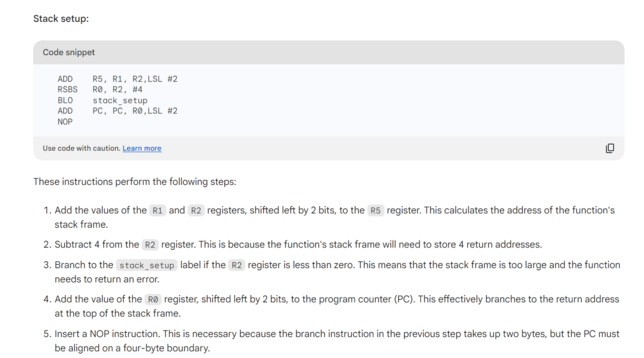
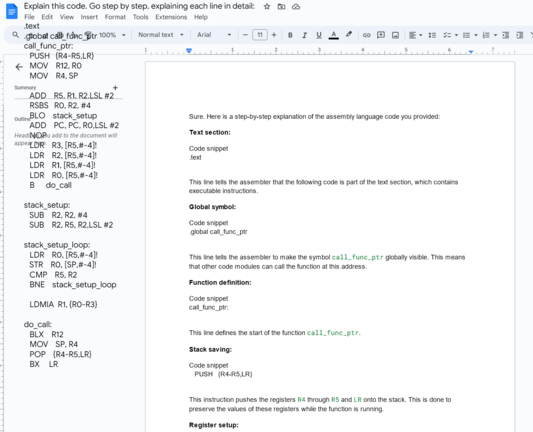
Bard is bad at explaining ARM assembler (asked it to explain https://app.assembla.com/spaces/chdk/subversion/source/HEAD/trunk/lib/armutil/callfunc.S with the comments stripped out) Basically, all of the "explanation" in the screenshot is wildly incorrect gobbledygook. The add pc,pc… is a switch statement (which goes to instructions bard didn't explain at all), and the NOP is there because reading PC actually gives you PC + 8. And in (non-thumb) ARM, instructions are always 4 bytes.
Full "explanation" https://paste.debian.net/1293459/
I thought #GoogleBard's "export conversation to a google doc" was broken, but it turns out it uses the entire prompt for the name, which ends up overflowing and hovering off to the left, unselectable and uneditable unless you click the name area
Wow, talk about a double standard, when #ChatGPT does it, it's just a harmless "hallucination" but when Sam does it, he's fired for being "not consistently candid in his communications"
(thanks Sam for your contribution to #SchadenfreudeFriday)
https://arstechnica.com/ai/2023/11/openai-fires-ceo-sam-altman-citing-less-than-candid-communications/

Is your Monday missing a multi-thousand word excruciatingly detailed explanation of how bad #GoogleBard #LLM #AI is at explaining / #ReverseEngineering #ARM #Assembly? Well then boy do I have a deal for you https://reedmideke.github.io/2023/11/20/google-bard-arm-assembly.html

"We asked them about it — and they deleted everything."
edit it just keeps getting more bizarre: "It wasn't just author profiles that the magazine repeatedly replaced. Each time an author was switched out, the posts they supposedly penned would be reattributed to the new persona, with no editor's note explaining the change in byline."
#AIIsGoingGreat https://futurism.com/sports-illustrated-ai-generated-writers

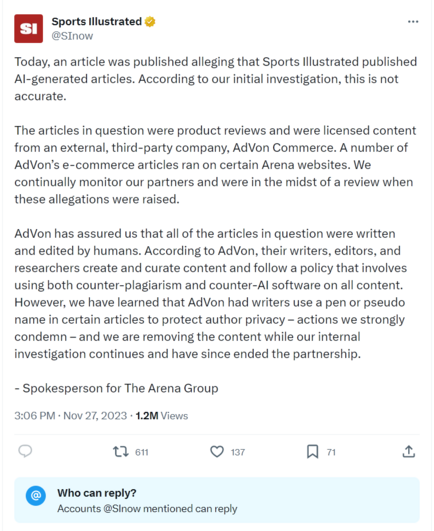
Update on that @futurism #SportsIllustrated #AI story: SI denies, claiming it was outsourced to AdVon who "has assured us that all of the articles in question were written and edited by humans." but uh, I dunno, guess someone should let AdVon, the definitely human copy writing company know their LinkedIn has been vandalized to say they're an AI company hiring programmers https://twitter.com/SInow/status/1729275460922622374

Sports Illustrated (@SInow) on X
Today, an article was published alleging that Sports Illustrated published AI-generated articles. According to our initial investigation, this is not accurate. The articles in question were product reviews and were licensed content from an external, third-party company, AdVon…
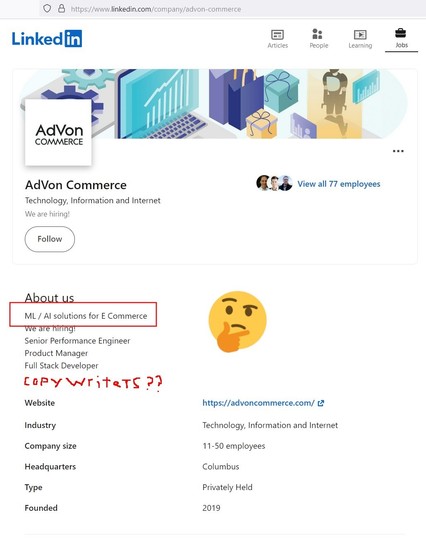
Oh and if anyone is looking for other outlets to check for "we pinky swear it's not #AI" churnalism, #AdVon helpfully gives you a list of high profile clients (claimed; lying or exaggerating about having big name customers is an extremely common SV startup tactic) https://advoncommerce.com/

Data point for the "LLMs can't infringe copyright because they don't contain or produce verbatim copies" crowd https://www.404media.co/google-researchers-attack-convinces-chatgpt-to-reveal-its-training-data/

Google Researchers’ Attack Prompts ChatGPT to Reveal Its Training Data
ChatGPT is full of sensitive private information and spits out verbatim text from CNN, Goodreads, WordPress blogs, fandom wikis, Terms of Service agreements, Stack Overflow source code, Wikipedia pages, news blogs, random internet comments, and much more.
"Chat alignment hides memorization" - Note *hides*, not *prevents*
As the authors also note, OpenAI "fixed" this by preventing the particular problematic prompt, but "Patching an exploit != Fixing the underlying vulnerability"
https://not-just-memorization.github.io/extracting-training-data-from-chatgpt.html

Can't be certain without more specifics but color me extremely skeptical that "#AI" producing thousands of targets is doing much more the laundering responsibility

New #ChatGPTLawyer dropped. Much like the ones in NY (Mata v. Avianca), it made up citations, he didn't check, and then doubled down when caught, initially blaming it on an intern
https://www.coloradopolitics.com/courts/disciplinary-judge-approves-lawyer-suspension-for-using-chatgpt-for-fake-cases/article_d14762ce-9099-11ee-a531-bf7b339f713d.html
https://www.coloradopolitics.com/courts/disciplinary-judge-approves-lawyer-suspension-for-using-chatgpt-for-fake-cases/article_d14762ce-9099-11ee-a531-bf7b339f713d.html

This hilarious in its own right, but it's also a great illustration of how people get tripped up by #LLM #AI bullshitting: One would expect an "AI" to at least know which brand AI it is, but of course, these LLMs don't actually know anything
Also the classic AI vendor response of promising to fix this particular case without any hint of acknowledging the underlying problem
Begging news orgs to stop reporting #AI company pitch decks as fact "Ashley [the bot] analyzes voters' profiles to tailor conversations around their key issues. Unlike a human, Ashley always shows up for the job, has perfect recall of all of Daniels' positions"
"…is now armed with another way to understand voters better, reach out in different languages (Ashley is fluent in over 20)"
"As far as the Court can tell, none of these cases exist" - The #ChatGPTLawyer / Trump world crossover no one asked for? https://arstechnica.com/tech-policy/2023/12/michael-cohens-lawyer-cited-three-fake-cases-in-possible-ai-fueled-screwup/

@reedmideke That is *chef's kiss*