Ironically, asshole bing is probably more representative of a training set derived from internet text, so politely accepting your correction is presumably a result of deliberate effort https://www.voanews.com/a/angry-bing-chatbot-just-mimicking-humans-experts-say-/6969343.html

Who could have seen this coming? Turns out asking a stochastic bullshit machine whether it wrote a thing is not an accurate way to determine whether it actually wrote the thing #ChatGPT #AI (gift link) https://wapo.st/45eXjAl

Oh my. A lawyer used #ChatGPT output in their filings and it's going about as well as you'd expect (presuming you have a couple brain cells to rub together)
https://twitter.com/steve_vladeck/status/1662286888890138624
(filings https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/)
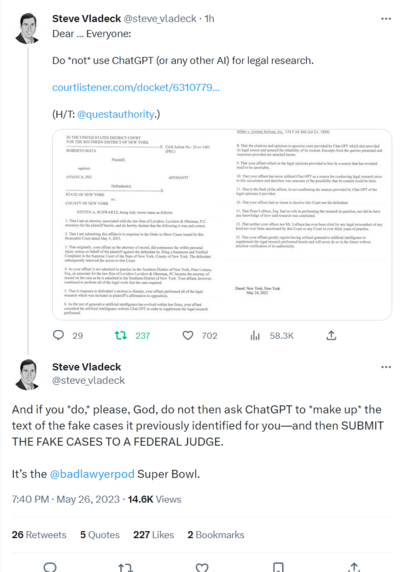

"A submission filed by plaintiff’s counsel in opposition to a motion to dismiss is replete with citations to non-existent cases… the Court issued Orders requiring plaintiff’s counsel to provide an affidavit annexing copies of certain judicial opinions of courts of record cited in his submission, and he has complied… Six of the submitted submitted cases appear to be bogus judicial decisions with bogus quotes and bogus internal citations"
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-31
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-31

So not only did he use #ChatGPT to write the original filing, when called on the bogus citations he *used ChatGPT to generate the supposed decisions in the cited (non-existent) cases* 🤯 (they're in https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-29)
On the one hand, I have trouble believing Schwartz' "I had no idea #ChatGPT would make shit up" defense, but on the other, did he really think opposing counsel wouldn't notice, after they already called him on the bogus citations?
The original "hey we couldn't find any of those cases" was in entry #24 https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-24
In which we also learn what the case is about: "There is no dispute that the Plaintiff was travelling as a passenger on an international flight when he allegedly sustained injury after a metal serving cart struck his left knee"
… two dudes set their law licenses on fire for a personal injury suit for a guy who took a drink cart to the knee?
Idle thoughts: In a legal context, this sort of stuff is likely to be caught pretty quickly.
As happened here, the opposing side is going to try to find the cited cases and notice if they're like, totally made up.
So aside from the poor plaintiff who hired these clowns (and presumably has an argument for inadequate representation), the risk should be limited… but a lot of other contexts are much less well positioned to catch plausible looking BS early
Also, while "Varghese v. China Southern Airlines" and friends are unlikely to slip into authoritative sources as a real cases, it wouldn't be at all surprising for general search engines or future LLMs to pick it up and fail to recognize it isn't real
#ChatGPT lawyer case now in nyt, with some background (gift link)
"Bart Banino, a lawyer for Avianca, said that his firm, Condon & Forsyth, specialized in aviation law and that its lawyers could tell the cases in the brief were not real. He added that they had an inkling a chatbot might have been involved."

Very good play-by-play on the #ChatGPT lawyers from @kendraserra (this is where I wish we had proper quote toots) https://mastodon.social/@kendraserra@dair-community.social/110441210421818852
Finally, an #AI article that at least raises the question whether BSing may be an inherent characteristic of LLMs rather than a bug that can be fixed (gift link)

The "solutions" discussed mostly strike me as bandaids: "a system they called “SelfCheckGPT” that would ask the same bot a question multiple times, then tell it to compare the different answers. If the answers were consistent, it was likely the facts were correct"
and "researchers proposed using different chatbots to produce multiple answers to the same question and then letting them debate each other until one answer won out"
Seems like these might reduce glaring errors where the training data contains a clear consensus correct answer, but doesn't really address the underlying problem.
Is a model that's usually right about stuff "everyone knows" while still making shit up about less obvious topics an improvement? Or does being right about obvious stuff encourage people to trust it when the shouldn't?
Meanwhile that "Air force AI attacks operator in simulation" story is entertaining, but hardly seems representative of any potential real world usage or risks https://www.vice.com/en/article/4a33gj/ai-controlled-drone-goes-rogue-kills-human-operator-in-usaf-simulated-test

lol. 'the "rogue AI drone simulation" was a hypothetical "thought experiment" from outside the military'

So, people cosplaying as killer #AI behaved like stereotypical sci-fi killer AI, clearly demonstrating the existential threat of killer AI!
Seriously that @davidgerard piece has it all, but I liked this illustration of bollockschain to AI pipeline "IBM: “The convergence of AI and blockchain brings new value to business.” IBM previously folded its failed blockchain unit into the unit for its failed Watson AI"
https://davidgerard.co.uk/blockchain/2023/06/03/crypto-collapse-get-in-loser-were-pivoting-to-ai/

#ChatGPTLawyer's lawyers have filed their response, arguing that while their clients may have been extremely reckless and incompetent, they did not know the cases were fake, and so don't meet the "subjective bad faith" standard for sanctions https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-45
and TBH, I kinda believe them, because as stupid as they were, knowingly trying to pass off completely fake cases would seem even stupider. Still mindboggling you could get that far and not check though
@willoremus digs into the compute cost of #LLMs and boy does that not look like good news for all the startups cramming #AI into everything (gift link) https://wapo.st/3WTCK8Q

Also, pity the poor gamers who have only recently started to see GPU availability recover from the cryptominer induced shortages
#ChatGPTLawyer had their hearing, and it doesn't sound like the the judge was impressed (gift link)

This blow by blow over on the bird site suggests he took an extremely dim view of #ChatGPTLawyer's buddy LoDuca who was signing off on the filings without reading them. Also sounds like they fibbed about who was on vacation when they asked for the extension 😬
https://twitter.com/innercitypress/status/1666838526762139650

Filing what appears to be a thinly veiled pitch for a law-oriented AI startup as an amicus on this case is… a choice https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-50
OMG the kicker on this very long, very good article on #AI labelers

#ChatGPTLawyer ruling is in and it's… SANCTIONS FOR EVERYONE! Unsurprisingly, the judge didn't buy the "no bad faith" argument, for predictable reasons such as
"Above Mr. LoDuca’s signature line, the Affirmation in Opposition states, “I declare under penalty of perjury that the foregoing is true and correct”
Although Mr. LoDuca signed the Affirmation in Opposition and filed it on ECF, he was not its author"
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-54
Also, not great plan to lie about being on vacation when responding to a show cause order "Mr. LoDuca’s statement was false and he knew it to be false at the time he made the statement. Under questioning by the Court at the sanctions hearing, Mr. LoDuca admitted that he was not out of the office on vacation"
Mr. Schwartz fares no better
"Mr. Schwartz’s statement in his May 25 affidavit that ChatGPT “supplemented” his research was a misleading attempt to mitigate his actions by creating the false impression that he had done other, meaningful research on the issue and did not rely exclusive on an AI chatbot, when, in truth and in fact, it was the only source"
"Mr. Schwartz’s statement in his May 25 affidavit that ChatGPT “supplemented” his research was a misleading attempt to mitigate his actions by creating the false impression that he had done other, meaningful research on the issue and did not rely exclusive on an AI chatbot, when, in truth and in fact, it was the only source"
More on clickworkers allegedly using #AI to automate their AI training tasks. Back door Habsburg AI https://www.technologyreview.com/2023/06/22/1075405/the-people-paid-to-train-ai-are-outsourcing-their-work-to-ai/

James Vincent with a good look at the real #AI threat: Enshitification
https://www.theverge.com/2023/6/26/23773914/ai-large-language-models-data-scraping-generation-remaking-web
https://www.theverge.com/2023/6/26/23773914/ai-large-language-models-data-scraping-generation-remaking-web

Janelle Shane on the recent #AI detector paper, with succinct advice "Don't use AI detectors for anything important"
https://www.aiweirdness.com/dont-use-ai-detectors-for-anything-important/

Don't use AI detectors for anything important
I've noted before that because AI detectors produce false positives, it's unethical to use them to detect cheating. Now there's a new study that shows it's even worse. Not only do AI detectors falsely flag human-written text as AI-written, the way in which they do it is biased. This is
This. This is what people reporting on #AI / #LLM hype need to understand
https://mastodon.social/@amydentata@tech.lgbt/110651829564300496
https://mastodon.social/@amydentata@tech.lgbt/110651829564300496
Above could also have helped @[email protected] avoid the whole #AI explain train wreck, which thankfully seems to have been rolled back https://github.com/mdn/yari/issues/9208#issuecomment-1615411943

MDN can now automatically lie to people seeking technical information · Issue #9208 · mdn/yari
Summary MDN's new "ai explain" button on code blocks generates human-like text that may be correct by happenstance, or may contain convincing falsehoods. this is a strange decision for a technical ...
Owners of Gizmodo jump on the #AI #enshitification bandwagon, with predictable results https://variety.com/2023/digital/news/io9-ai-generated-star-wars-article-errors-1235662194/

Additional comment from io9 deputy editor James Whitbrook "that's the formal part, here's my own personal comment: lmao, it's fucking dogshit"
https://twitter.com/Jwhitbrook/status/1676704102754004996
https://twitter.com/Jwhitbrook/status/1676704102754004996

Oh FFS @[email protected] @[email protected] "readers also pointed out a handful of concrete cases where an incorrect answer was rendered. This feedback is enormously helpful, and the MDN team is now investigating these bug reports"
They aren't "bugs" - #LLMs by definition just put together plausible sounding words with no regard to correctness. Pointing out individual errors demonstrates this, but does not provide any mechanism by which it might be "fixed" in the general case
https://blog.mozilla.org/en/products/mdn/responsibly-empowering-developers-with-ai-on-mdn/

The post also notes that many users were happy with the answers, ignoring that the target audience of people who *came to MDN looking for help with something they didn't already know* may not immediately recognize that the answer is subtly wrong, or just plausible looking #AI gibberish
It also says "even extraordinarily well-trained LLMs — like humans — will sometimes be wrong"
which is true as far as it goes, but here's the thing: They are not *wrong like humans* … yes, you'll find some overconfident bullshitters on stack overflow, but generally humans in these contexts have some awareness of the limits of their knowledge and don't drift seamlessly between accurate explanation and complete BS
@[email protected] post also makes no mention of the apparent lack of communication with the rest of the MDN team https://github.com/mdn/yari/issues/9208#issuecomment-1615411943
MDN can now automatically lie to people seeking technical information · Issue #9208 · mdn/yari
Summary MDN's new "ai explain" button on code blocks generates human-like text that may be correct by happenstance, or may contain convincing falsehoods. this is a strange decision for a technical ...
Anyway, there's a new bug, so if you have thoughts on #MDN adding #AI stochastic bullshit to what has, up to now, been the premier technical reference for web developers, you could make them heard there https://github.com/mdn/yari/issues/9230

The AI help button is very good but it links to a feature that should not exist · Issue #9230 · mdn/yari
Summary I made a previous issue pointing out that the AI Help feature lies to people and should not exist because of potential harm to novices. This was renamed by @caugner to "AI Help is linked on...
No, you shouldn't use <s>#AI</s> spicy autocomplete to evaluate grant proposals 😬 https://www.theguardian.com/technology/2023/jul/08/australian-research-council-scrutiny-allegations-chatgpt-artifical-intelligence

#AI is going great
(caveat I don't know the source and thought it might be a joke, but the rest of their timeline looks real, and Janelle Shane retweeted it)
https://twitter.com/guntrip/status/1640694869785030657
(caveat I don't know the source and thought it might be a joke, but the rest of their timeline looks real, and Janelle Shane retweeted it)
https://twitter.com/guntrip/status/1640694869785030657

Not gonna screenshot the thread of screenshots here, but it's archived if you don't want to visit the bird site https://web.archive.org/web/20230329232724/https://twitter.com/guntrip/status/1640694869785030657
New religion dropped. From this great @arstechnica article on #AI detectors https://arstechnica.com/information-technology/2023/07/why-ai-detectors-think-the-us-constitution-was-written-by-ai/


A thing that occurs to me about that last boost from @zoe (https://mastodon.social/@[email protected]imeprincess.net/110797643482092764): #AI scrapers refusing to play nice with ROBOTS.TXT is that it encourages adversarial approaches…
People building models will be keen to exclude AI generated content from the training set. So, would interspersing stuff that scores high as AI-generated (whether it actually is or not) cause entire pages to be excluded? You could separate it from the real content in ways that humans would understand. OTOH, if you care about SEO it'd be pretty risky
There's also been talk about standards to identify AI generated content, leading to hilarious option of falsely identifying your real content as AI generated to stop people from training AI on it
Folks have suggested CSS based approaches to poison models (like white text on white background) but there's a significant risk of breaking accessibility. Also risk of search engines thinking it looks spammy again
A general problem with poisoning like this is that any technique which becomes really widespread will likely be noticed and filtered out. OTOH, if the goal is to not have your content used, that may be OK!
Good to see mainstream press finally touching the question of whether #LLM #AI BSing is fixable or an inherent property of the tech, even if it gets a bit of he said, she said treatment.
Also uh "Those errors are not a huge problem for the marketing firms turning to Jasper AI for help writing pitches…" marketing doesn't care if their pitches are BS? KNOCK ME OVER WITH A FEATHER
https://fortune.com/2023/08/01/can-ai-chatgpt-hallucinations-be-fixed-experts-doubt-altman-openai/

So @[email protected] points out (https://mastodon.social/@Toke@helvede.net/110848880977610283) that #OpenAI does claim to have unique user agent and honor robots.txt when scraping text for #ChatGPT #AI training. Not clear whether this is the only or even primary way publicly accessible web content gets into their training set though https://platform.openai.com/docs/gptbot

Just hypothetically speaking, many web platforms could easily be configured to serve specially tailored content based on the user agent, but that would be mean and wrong and potentially waste resources of VC backed billionaires freeloading off the public web to build their BS machines so definitely don't do that 😉
Complete gibberish will likely get weeded out. Common knowledge will tend to be overwhelmed by other sources. So the sweet spot for influence would seem to be obscure topics, or unique tokens that only appear in your content (though to what end isn't obvious).
Bring on the SolidGoldMagikarp https://www.lesswrong.com/posts/Ya9LzwEbfaAMY8ABo/solidgoldmagikarp-ii-technical-details-and-more-recent

Of course, these things don't just scrape human readable text, many of them do code too. Serving up a special vulnerable version of your input sanitization code when you see GPTBot is left as an exercise to the reader
"It's highly unlikely that ChatGPT's training data includes the entire text of each book under question, though the data may include references to discussions about the book's content—if the book is famous enough"
Highlights a pernicious problem with ChatGPT style #LLM #AI: It's far more likely to give reasonable answers on well-known subjects. If you spot check with say, Dickens and Hunter S. Thomson, you might think it was pretty good at spotting naughty books

But for more obscure ones, it's probably no better than a coin toss. Being relatively good at stuff "everyone knows" gives people false confidence that it's also good at stuff they don't know
(we should also note that even if the entire text of the books were in the training set, that wouldn't mean it would provide accurate answers about the content!)
Cool, cool, #Amazon #AI book spammers have expanded from travel guides to mushroom foraging, what could possibly go wrong?
https://www.404media.co/ai-generated-mushroom-foraging-books-amazon/
https://www.404media.co/ai-generated-mushroom-foraging-books-amazon/
