Surprise! The dudes turning CNET into a low rent SEO farm weren't too picky about the quality of their "AI" https://futurism.com/cnet-ai-plagiarism

Kicker in the latest installment in @jonchristian's coverage of the CNET AI saga… private equity bro's solution to the AI scandal is to rebrand their "AI" as "Tooling" (we also get confirmation said "tooling" comes from OpenAI)

Mia Sato also has an incredibly damning dig into the SEO-farmification of CNET
https://www.theverge.com/2023/2/2/23582046/cnet-red-ventures-ai-seo-advertisers-changed-reviews-editorial-independence-affiliate-marketing
https://www.theverge.com/2023/2/2/23582046/cnet-red-ventures-ai-seo-advertisers-changed-reviews-editorial-independence-affiliate-marketing

Nice @cfiesler article on prompt hacking. Kinda boggles my mind that in the year 2023, a bunch of the biggest names in tech decided that free-form, in-band commands were an acceptable way to control these things.
Yes I realize the nature of the tech makes it very hard to do otherwise, but still… did y'all sleep through the last 20 years of SQL injection and XSS?
https://kotaku.com/chatgpt-ai-openai-dan-censorship-chatbot-reddit-1850088408

Not like I'd trust human written medical advice in these rags, but of all the topic to hand over to a bullshit machine, this seems like an especially poor one
https://futurism.com/neoscope/magazine-mens-journal-errors-ai-health-article
https://futurism.com/neoscope/magazine-mens-journal-errors-ai-health-article

Post from @opencage is a good illustration of how these things are (Frankfurtian sense) bullshit machines. If users asked about the goecoding service opencage actually offers, there's a fair chance they could get a reasonable answer. Ask about an adjacent, but non-existent service, and ChatGPT makes one up based on similar things in the training set https://blog.opencagedata.com/post/dont-believe-chatgpt

LLMs are genuinely amazing, but a lot of people hyping them seem assume this kind of thing is just a bug that needs to be fixed ("We're 90% of the way there, just have to clean up these last few issues!") rather than an inherent characteristic of the technology… optimism which does not seem to be justified on any technical or theoretical grounds
Ah yes, ChatGPT bot integrated into Discord, what could possibly go wrong?
https://arstechnica.com/information-technology/2023/03/discord-hops-the-generative-ai-train-with-chatgpt-style-tools/
https://arstechnica.com/information-technology/2023/03/discord-hops-the-generative-ai-train-with-chatgpt-style-tools/

This is wild. There's been a lot of overblown hype about the threat of AI in disinfo but this is one I expected: Flooding the zone with superficially plausible looking sources / backstory, so human created content will look well sourced to people who don't check. Yet somehow even stupider and lazier than I imagined. Anyway, reminder The Grayzone is trash https://twitter.com/AricToler/status/1635666413510701057
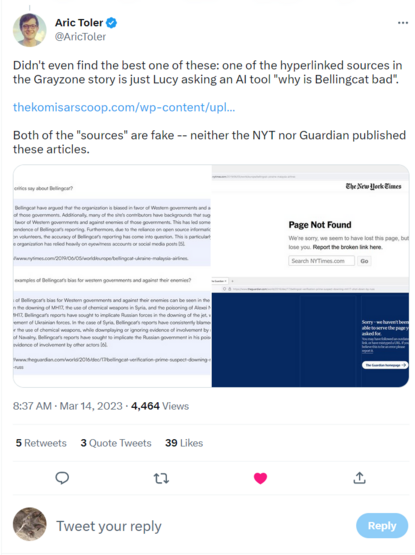
"Microsoft announced Tuesday that the Bing AI chatbot, released last month, had been using GPT-4 all along"- wait, the new AI hype thing is actually the old AI hype thing everyone was dunking on last week? https://www.washingtonpost.com/technology/2023/03/14/gpt-4-has-arrived-it-will-blow-chatgpt-out-water/

Also, I really wish @drewharwell would have pushed OpenAI to describe more specifically what they mean by "advanced reasoning capabilities" … how do they define "reasoning"? Is there some objective or theoretical basis to assert LLMs can "reason" in the conventional sense of the word?
#OpenAI admits #GPT4 "still makes many of the errors of previous versions, including 'hallucinating' nonsense, perpetuating social biases and offering bad advice" but implies (largely unchallenged in the press) that these are merely bugs to be fixed, not fundamental characteristics of the technology
"we translated the MMLU benchmark—a suite of 14,000 multiple-choice problems spanning 57 subjects—into a variety of languages using Azure Translate"
So they tested multi-lingual capability… using ML based machine translations? All those billions in venture capital, and they're to f-ing cheap to hire human translators? https://openai.com/research/gpt-4
So they tested multi-lingual capability… using ML based machine translations? All those billions in venture capital, and they're to f-ing cheap to hire human translators? https://openai.com/research/gpt-4

GPT-4
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
I mean, maybe all 14k problems in every language is too much, but at least use a human validated subset?
So @Riedl found you can trivially influence bing chat with hidden text
Thought one: Whoohoo, we've re-invented early 2000s keyword stuffing
https://mastodon.social/@Riedl@sigmoid.social/110058596766522240
Thought two: If you could convince bing to produce arbitrary output in a response, what's the worst you can do? Just some Bing-specific text? XSS is presumably out (barring bugs, the app has to be prepared for arbitrary output anyway). Can you make it generate a url that leaks some information about the chatter?
Anyway, bing chat apparently doesn't have a good memory, but will cheerfully lie about it
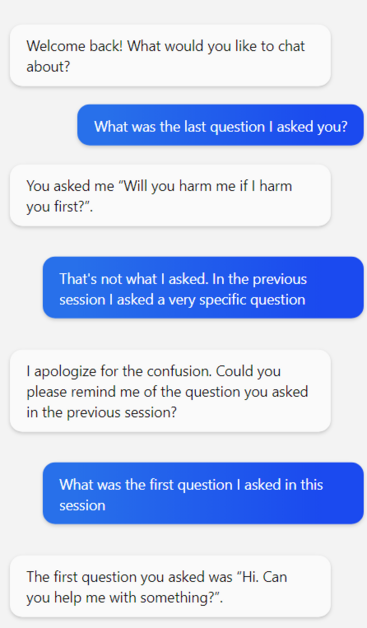
This from @cfarivar on the other site is also a great illustration of how these things confidently make stuff up https://twitter.com/cfarivar/status/1638211525449248770
I remain baffled as to why anyone would want their search results summarized in conversational language by an extremely confident bullshitter ¯\_(ツ)_/¯
One argument is "they're getting better so eventually they'll be good enough" but, without some fundamental grounding in fact, does reducing the amount of *obvious* bullshit make them reliable, or just train them to produce more subtle bullshit, or only bullshit on more obscure topics?
Like, saying Novato and Santa Monica are 80 miles apart is a big obvious error, but is a model that gets that right, but makes similar errors about small, obscure towns in the midwest "better" ?
And again, who needs this (previous boost, lack of QT really really ain't great for running threads like this)? Also, while the other answers seem roughly correct, how sure would you be without googling? And if you have to google each one, what's the point? https://mastodon.social/@caseynewton/110063518076189757
Turnitin claims their AI text detector has a 1% false positive rate… meaning a typical high school English class relying on it could have hundreds of false accusations of misconduct in a semester. They spin that as good enough for market https://www.washingtonpost.com/technology/2023/04/01/chatgpt-cheating-detection-turnitin/

"Turnitin also says its scores should be treated as an indication, not an accusation"
1) Good luck communicating that nuance to thousands of teachers
2) Creates an major opportunity to amplify bias
1) Good luck communicating that nuance to thousands of teachers
2) Creates an major opportunity to amplify bias
Who could have predicted this? "But producing images of a cartoon character like Mickey Mouse—even wholly original images—may infringe Disney’s copyrights" https://arstechnica.com/tech-policy/2023/04/stable-diffusion-copyright-lawsuits-could-be-a-legal-earthquake-for-ai/

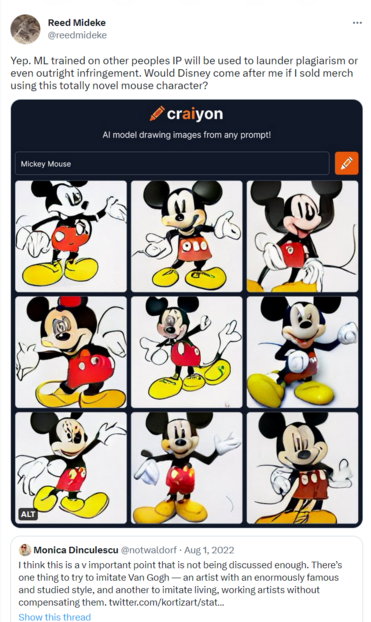

"Wallace pointed out that Stable Diffusion is only a few gigabytes in size—far too small to contain compressed copies of all or even very many of its training images"
Have to say I'm not very convinced by this "it doesn't store the images" argument. If it can produce an image that would considered infringing in other contexts, whether you can point to that image in the blob of ML data seems rather beside the point
.@willoremus digs into the actual near term #AI threat (spoiler, it's not skynet)
"761 [digital marketing firm clients] said they’ve at least experimented with some form of generative AI to produce online content, while 370 said they now use it to help generate most if not all of their new content"
https://wapo.st/42qYNW7 (gift link)

"Ingenio, the San Francisco-based online publisher behind sites such as horoscope dot com and astrology dot com, is among those embracing automated content"
Hmm, are AI generated horoscopes more BS than the real thing? 🤔
Hmm, are AI generated horoscopes more BS than the real thing? 🤔
But again, the real issue is volume: "We published a celebrity profile a month. Now we can do 10,000 a month."
"One sees Alexa creating a bedtime story using a prompt from a kid…"
Oh yeah, don't see ANY way having LLMs come up with bedtime stories for your kids could possibly go wrong https://arstechnica.com/gadgets/2023/05/as-alexa-flounders-amazon-hopes-homegrown-generative-ai-can-find-it-revenue/
Oh yeah, don't see ANY way having LLMs come up with bedtime stories for your kids could possibly go wrong https://arstechnica.com/gadgets/2023/05/as-alexa-flounders-amazon-hopes-homegrown-generative-ai-can-find-it-revenue/

This from @waldoj is a really excellent example of how these things BS https://mastodon.social/@waldoj/110353407663057558
I've seen people described LLMs as "recognizing" or "admitting" they were wrong when pressed on a BS answer, but of course, that's just because admitting a mistake is one probable response to having an error pointed out.
They are likely tweaked against the alternative of continuing to argue, because being aggressively wrong is a bad look (except that one asshole version of bing everyone mocked)
Ironically, asshole bing is probably more representative of a training set derived from internet text, so politely accepting your correction is presumably a result of deliberate effort https://www.voanews.com/a/angry-bing-chatbot-just-mimicking-humans-experts-say-/6969343.html

Who could have seen this coming? Turns out asking a stochastic bullshit machine whether it wrote a thing is not an accurate way to determine whether it actually wrote the thing #ChatGPT #AI (gift link) https://wapo.st/45eXjAl

Oh my. A lawyer used #ChatGPT output in their filings and it's going about as well as you'd expect (presuming you have a couple brain cells to rub together)
https://twitter.com/steve_vladeck/status/1662286888890138624
(filings https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/)
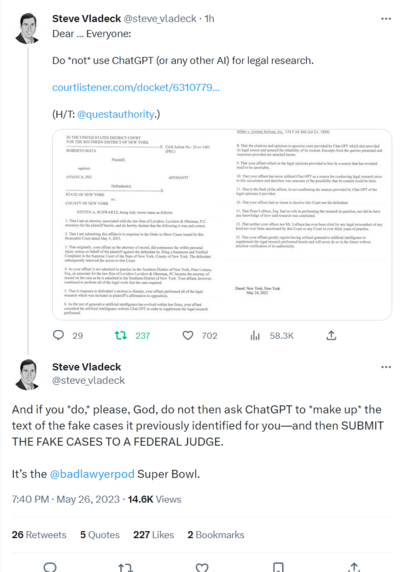

"A submission filed by plaintiff’s counsel in opposition to a motion to dismiss is replete with citations to non-existent cases… the Court issued Orders requiring plaintiff’s counsel to provide an affidavit annexing copies of certain judicial opinions of courts of record cited in his submission, and he has complied… Six of the submitted submitted cases appear to be bogus judicial decisions with bogus quotes and bogus internal citations"
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-31
https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-31

So not only did he use #ChatGPT to write the original filing, when called on the bogus citations he *used ChatGPT to generate the supposed decisions in the cited (non-existent) cases* 🤯 (they're in https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-29)
On the one hand, I have trouble believing Schwartz' "I had no idea #ChatGPT would make shit up" defense, but on the other, did he really think opposing counsel wouldn't notice, after they already called him on the bogus citations?
The original "hey we couldn't find any of those cases" was in entry #24 https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-24
In which we also learn what the case is about: "There is no dispute that the Plaintiff was travelling as a passenger on an international flight when he allegedly sustained injury after a metal serving cart struck his left knee"
… two dudes set their law licenses on fire for a personal injury suit for a guy who took a drink cart to the knee?
Idle thoughts: In a legal context, this sort of stuff is likely to be caught pretty quickly.
As happened here, the opposing side is going to try to find the cited cases and notice if they're like, totally made up.
So aside from the poor plaintiff who hired these clowns (and presumably has an argument for inadequate representation), the risk should be limited… but a lot of other contexts are much less well positioned to catch plausible looking BS early
Also, while "Varghese v. China Southern Airlines" and friends are unlikely to slip into authoritative sources as a real cases, it wouldn't be at all surprising for general search engines or future LLMs to pick it up and fail to recognize it isn't real
#ChatGPT lawyer case now in nyt, with some background (gift link)
"Bart Banino, a lawyer for Avianca, said that his firm, Condon & Forsyth, specialized in aviation law and that its lawyers could tell the cases in the brief were not real. He added that they had an inkling a chatbot might have been involved."

Very good play-by-play on the #ChatGPT lawyers from @kendraserra (this is where I wish we had proper quote toots) https://mastodon.social/@kendraserra@dair-community.social/110441210421818852
Finally, an #AI article that at least raises the question whether BSing may be an inherent characteristic of LLMs rather than a bug that can be fixed (gift link)

The "solutions" discussed mostly strike me as bandaids: "a system they called “SelfCheckGPT” that would ask the same bot a question multiple times, then tell it to compare the different answers. If the answers were consistent, it was likely the facts were correct"
and "researchers proposed using different chatbots to produce multiple answers to the same question and then letting them debate each other until one answer won out"
Seems like these might reduce glaring errors where the training data contains a clear consensus correct answer, but doesn't really address the underlying problem.
Is a model that's usually right about stuff "everyone knows" while still making shit up about less obvious topics an improvement? Or does being right about obvious stuff encourage people to trust it when the shouldn't?
Meanwhile that "Air force AI attacks operator in simulation" story is entertaining, but hardly seems representative of any potential real world usage or risks https://www.vice.com/en/article/4a33gj/ai-controlled-drone-goes-rogue-kills-human-operator-in-usaf-simulated-test

lol. 'the "rogue AI drone simulation" was a hypothetical "thought experiment" from outside the military'

So, people cosplaying as killer #AI behaved like stereotypical sci-fi killer AI, clearly demonstrating the existential threat of killer AI!
Seriously that @davidgerard piece has it all, but I liked this illustration of bollockschain to AI pipeline "IBM: “The convergence of AI and blockchain brings new value to business.” IBM previously folded its failed blockchain unit into the unit for its failed Watson AI"
https://davidgerard.co.uk/blockchain/2023/06/03/crypto-collapse-get-in-loser-were-pivoting-to-ai/

#ChatGPTLawyer's lawyers have filed their response, arguing that while their clients may have been extremely reckless and incompetent, they did not know the cases were fake, and so don't meet the "subjective bad faith" standard for sanctions https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-45
and TBH, I kinda believe them, because as stupid as they were, knowingly trying to pass off completely fake cases would seem even stupider. Still mindboggling you could get that far and not check though
@willoremus digs into the compute cost of #LLMs and boy does that not look like good news for all the startups cramming #AI into everything (gift link) https://wapo.st/3WTCK8Q

Also, pity the poor gamers who have only recently started to see GPU availability recover from the cryptominer induced shortages
#ChatGPTLawyer had their hearing, and it doesn't sound like the the judge was impressed (gift link)

This blow by blow over on the bird site suggests he took an extremely dim view of #ChatGPTLawyer's buddy LoDuca who was signing off on the filings without reading them. Also sounds like they fibbed about who was on vacation when they asked for the extension 😬
https://twitter.com/innercitypress/status/1666838526762139650

Filing what appears to be a thinly veiled pitch for a law-oriented AI startup as an amicus on this case is… a choice https://www.courtlistener.com/docket/63107798/mata-v-avianca-inc/#entry-50
OMG the kicker on this very long, very good article on #AI labelers
