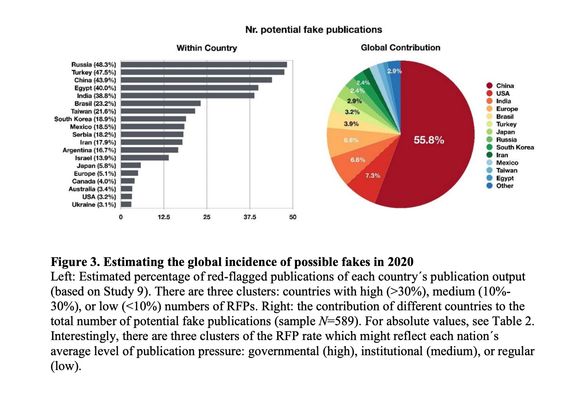
This week, Science published a stunningly irresponsible news story entitled "Fake scientific papers are alarmingly common" and claiming that upward of 30% of the scientific literature is fake.
https://www.science.org/content/article/fake-scientific-papers-are-alarmingly-common
Below, the first two paragraphs of the story.
Headline and intro notwithstanding, the story itself later notes that the detector doesn't actually work and flags nearly half of real papers as fake. Does the reporter just not understand that?
h/t @Hoch