Digitale Belege sichern: Internet Archive nutzen und selbst anlegen – Mein Beitrag bei der Netzwerk Recherche 2026
Wie sollen wir festhalten, was wir im Internet finden? Mit einem Screenshot? Ein Screenshot fast so schnell gefälscht wie er gemacht wurde. Entwickler-Tools öffnen, im HTML den Text ändern, fertig. Schon ist aus einem möglich auf der Startseite von Netzwerk Recherche ein unmöglich geworden.
echter Screenshot
gefälschter Screenshot
Das war der Einstieg meines Vortrags bei der Netzwerk […]
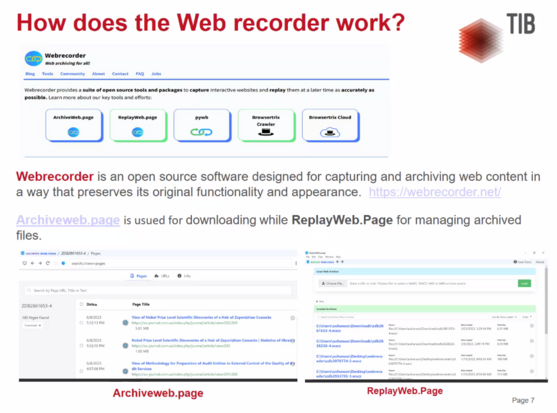
https://katharinabrunner.de/2026/06/digitale-belege-sichern-internet-archive-nutzen-und-selbst-anlegen-mein-beitrag-bei-der-netzwerk-recherche-2026/ #browsertrix #dataJournalism #DigitalArchive #InternetArchive #Journalismus #webarchiving #webrecorder