Kolmogorov-Arnold Networks: More Interpretable Neural Network
https://arxiv.org/abs/2404.19756
https://github.com/KindXiaoming/pykan
https://news.ycombinator.com/item?id=41162676
https://spectrum.ieee.org/kan-neural-network
https://en.wikipedia.org/wiki/Universal_approximation_theorem
* MLP: fixed activation functions on nodes (neurons)
* KAN: learnable activation FUNCTIONS on edges (weights)
* KAN: no linear weights at all: wt parameters replaced by functions
* much smaller KAN can achieve comparable/better accuracy than much larger MLP
#ML #NeuralNetworks #KolmogorovArnold #MLP #perceptrons
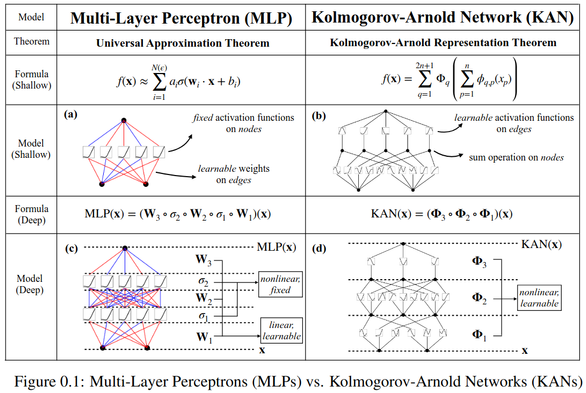

KAN: Kolmogorov-Arnold Networks
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes ("neurons"), KANs have learnable activation functions on edges ("weights"). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.

TSMixer: An all-MLP Architecture for Time Series Forecast-ing
Real-world time-series datasets are often multivariate with complex dynamics. To capture this complexity, high capacity architectures like recurrent- or attention-based sequential deep learning...
Transformer for Partial Differential Equations’ Operator Learning
Zijie Li, Kazem Meidani, Amir Barati Farimani
Action editor: Tie-Yan Liu.
https://openreview.net/forum?id=EPPqt3uERT
#attention #perceptrons #convolutional
Transformer for Partial Differential Equations’ Operator Learning
Data-driven learning of partial differential equations' solution operators has recently emerged as a promising paradigm for approximating the underlying solutions. The solution operators are...
Modern researchers and practitioners of
#NeuralNetworks should read the classic book "
#Perceptrons: An Introduction to Computational Geometry" (1969) by Minsky and Papert, because every proponent should know the main arguments of the detractors.
https://en.wikipedia.org/wiki/Perceptrons_(book)Perceptrons (book) - Wikipedia
Transformer for Partial Differential Equations’ Operator Learning
Data-driven learning of partial differential equations' solution operators has recently emerged as a promising paradigm for approximating the underlying solutions. The solution operators are...
“We’re not on the brink of major technological development here. We’re in the middle of some fiddling at the edges of what came before… Just like the algorithms, we’re stuck repeating the aesthetics…” —Caleb Gamman in “Algorithms”
https://youtu.be/MravA_dgUkQ
#AI #algorithms #algorithm #ArtificialIntelligence #perceptrons #NeuralNetworks #NeuralNetworks #AIWinter #Tesla

Artifice of Intelligence | CYBERGUNK 01
At
#NPS2018 hosted by @
[email protected] and listening to @
[email protected] speaking about how
#AI and
#ML are affecting
#photography and journalism. Pictured slide referring to 1950s intelligence agency attempts at using
#perceptrons.
