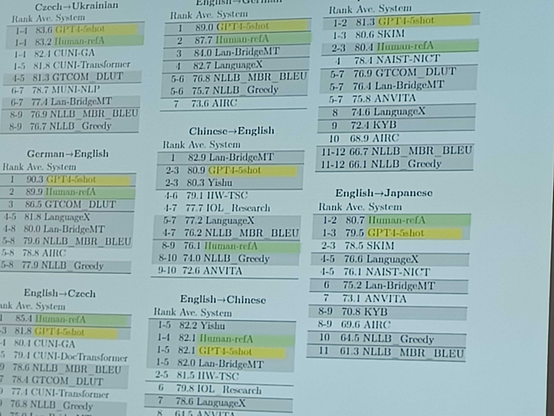
Findings from #WMT23
Our Chat4 friend is in the winning group across tasks
Most submissions still use from scratch training
Less constrained (low resource) submissions than before
More test suit submissions!
Low resource results TBD (tech issue)
#EMNLP2023 #WMT #neuralEmpty #LLMs
Our Chat4 friend is in the winning group across tasks
Most submissions still use from scratch training
Less constrained (low resource) submissions than before
More test suit submissions!
Low resource results TBD (tech issue)
#EMNLP2023 #WMT #neuralEmpty #LLMs