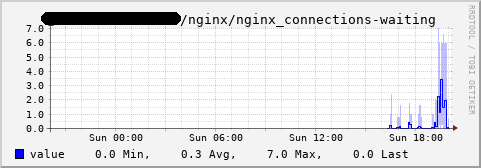
Stupid (not) nerd thing of the day: have #collectd regularly run a #curl command that tells #uptimekuma the server hidden far deep behind NAT is still alive.
More work on the #SolarCluster tonight. Using #Zephyr to bridge between #collectd and some INA219 current shunt monitors.
The code runs on a Raspberry Pi Pico, and enumerates two USB CDC-ACM UART devices. One is a console, the other is a Modbus/RTU slave.
Two things I learned:
1. Your first CDC-ACM UART is easy, but a second one is a royal PITA.
2. Zephyr's Modbus stack assumes you have dedicated callback functions for each and every Modbus unit you create, with no concept of passing a user pointer or a unit ID to the callback function.
I had thought of a scheme where I had 3 units, the unit ID being equal to the I²C address of the slave, and just registers for voltage, current and power (Vshunt is not exposed by the Zephyr driver).
Nope, I've had to use one unit ID, and just offset the register numbers. But, whatever… I have a bridge now. I'll put in some settings interface so I can adjust scaling (the Zephyr driver assumes a shunt with a resistance in whole milliohms, mine is 500µohms) and we should be in business.
Code is a work-in-progress, but you can see it here: https://codeberg.org/sjlongland/modbus-ina219-bridge