discovered the "Trusted contact" tab in the chatGPT settings
i mean in a way its outsourcing the safety of the product to other humans but you know what, i think thats actually a good thing they did there, even if its not for the right intention
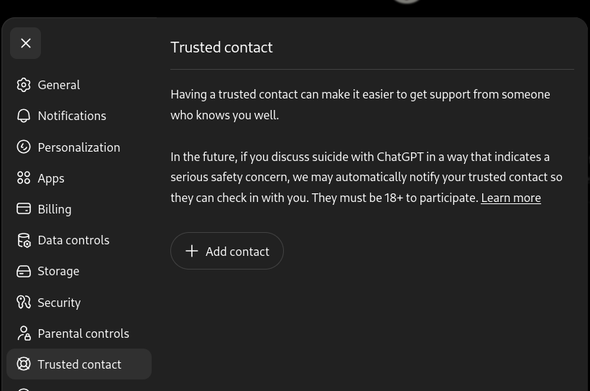
discovered the "Trusted contact" tab in the chatGPT settings
i mean in a way its outsourcing the safety of the product to other humans but you know what, i think thats actually a good thing they did there, even if its not for the right intention
https://winbuzzer.com/2026/06/03/microsoft-assert-turns-ai-agent-policies-into-tests-xcxwbn/
Microsoft has released ASSERT, an open-source framework that turns AI-agent policies into executable tests so developers can catch failures before deployment.
#AI #Microsoft #AIAgents #AgenticAI #AISafety #AIDevelopment #OpenSourceAI #Developers #MicrosoftAI
AAlso the vulnerability of undersea internet infrastructure is currently in the spotlight, the Australian Government has appointed a General Manager of the new AI Safety Institute and Malaysia’s social media minimum age legislation came into effect this week.
Researchers say ChatGPT, Gemini, and Grok can generate realistic fake IDs
https://fed.brid.gy/r/https://nerds.xyz/2026/06/ai-fake-id-chatgpt-gemini-grok/

SAP Tightens Grip on API Access to Shore Up AI Stability
SAP is limiting API access to make its AI safer and more reliable. This affects how developers connect to SAP systems.
SAP is putting stricter rules on how people can access its systems through APIs. This is to make sure its AI tools work safely and correctly.
#SAPAPI, #AISafety, #TechNews, #SAPAI, #DataSecurity
https://newsletter.tf/sap-limits-api-access-for-ai-safety/
Florida is the first state to file a lawsuit against OpenAI and its Chief Executive Sam Altman over AI harms and the role it played in a campus mass shooting last year.
Our friends at Wall Street Journal have offered this gift link to our readers:
https://flip.it/CHRerx
For more stories like this, follow our Flipboard Magazine on our app and receive our daily Tech Briefing newsletter:
https://flipboard.com/@thenewsdesk/top-stories-in-tech-lipvqk8vy
#OpenAI #Florida #AISafety

https://winbuzzer.com/2026/06/02/anthropic-reveals-315-browser-agent-hijack-rate-xcxwbn/
Anthropic has disclosed a 31.5% prompt-injection success rate for Claude's browser agent before safeguards, showing how hostile web instructions can reach live tools.
#AI #Anthropic #Claude #AIModels #AIAgents #AgenticAI #AISafety #AISecurity #EnterpriseAI