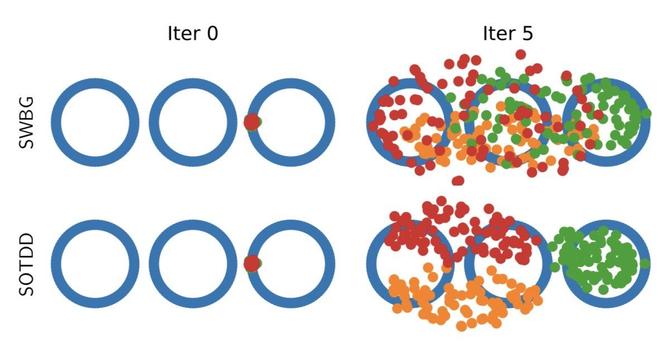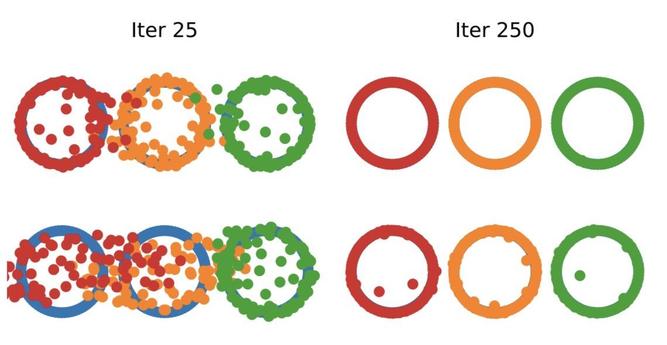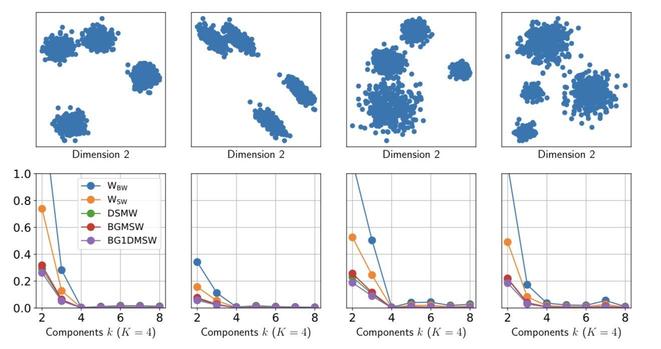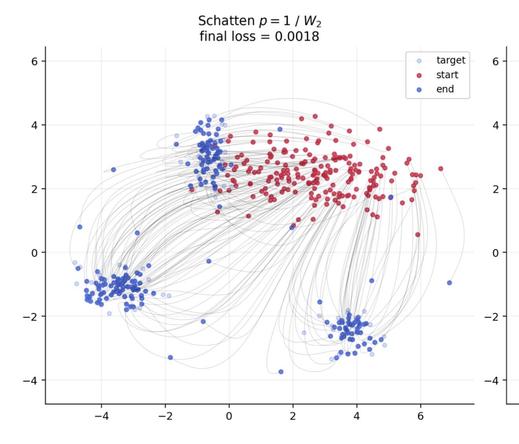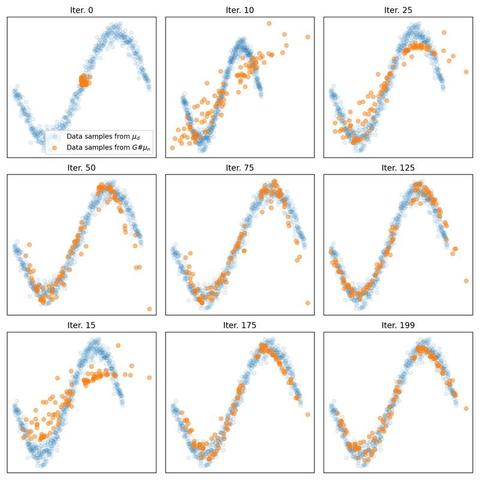
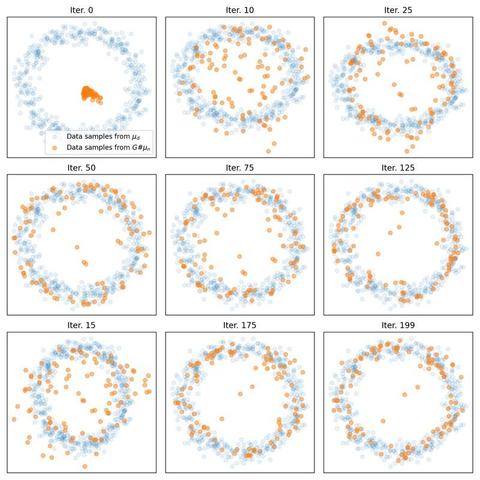
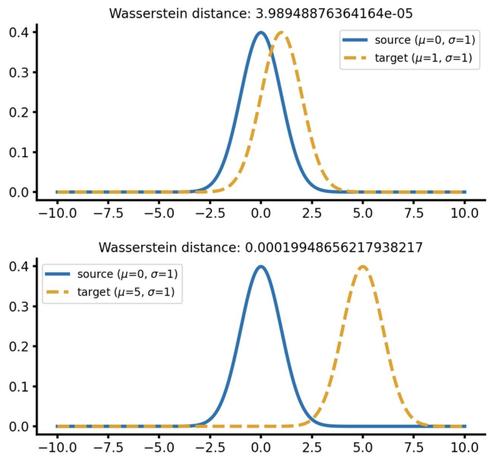
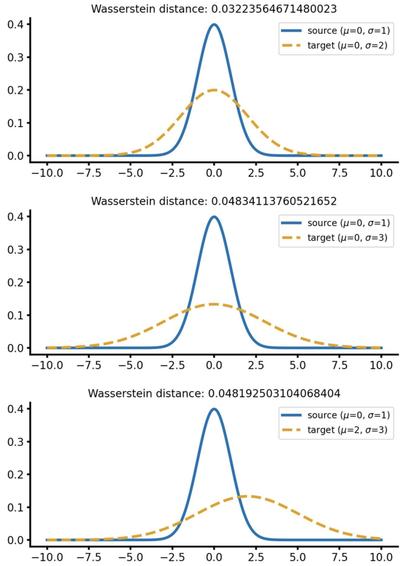
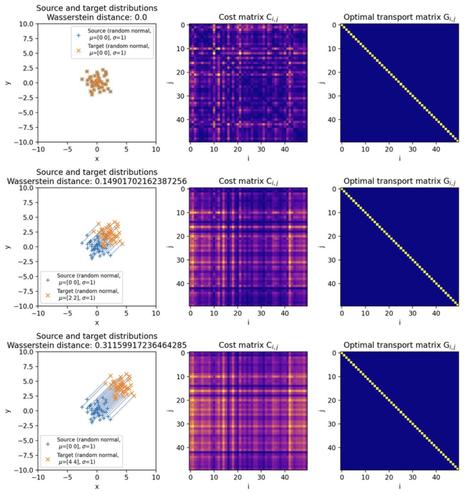
📐📚New study on #WassersteinDistance: Bonet et al. study #geodesic rays in #Wasserstein space and derive conditions for their existence. They show that #Busemann functions can be computed via #OT, with closed-form solutions for 1D and Gaussian cases. This enables efficient sliced distances for labeled datasets, closely matching classical metrics at lower cost and supporting dataset “flows” for #TransferLearning.