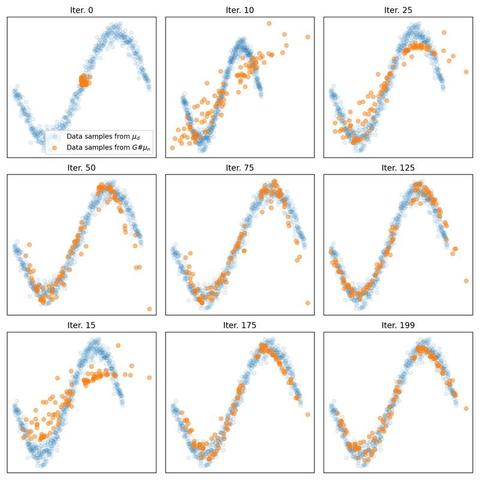
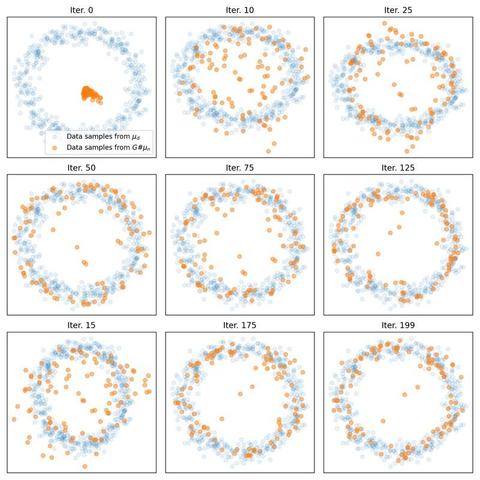
Eliminating the middleman: You can apply the computation of the #Wasserstein distance even more directly in #WassersteinGANs (#WGANs), eliminating the need for a discriminator.
🌎 https://www.fabriziomusacchio.com/blog/2023-07-30-wgan_with_direct_wasserstein_distance/

Eliminating the middleman: Direct Wasserstein distance computation in WGANs without discriminator
We explore an alternative approach to implementing WGANs. Contrasting from the standard implementation that requires both a generator and discriminator, the method discussed here employs the optimal transport to compute the Wasserstein distance directly between the real and generated data distributions, eliminating the need for a discriminator.