Design Milk : The EVA Tote System From PARSEL Might Be the Only Bag You Need https://design-milk.com/the-eva-tote-system-from-parsel-might-be-the-only-bag-you-need/ #Style+Fashion #bagcollection #fashiondesign #Lifestyle #bagdesign #beachtote #NurAbbas #totebags #totebag #PARSEL #totes #Main #bags #tote #bag

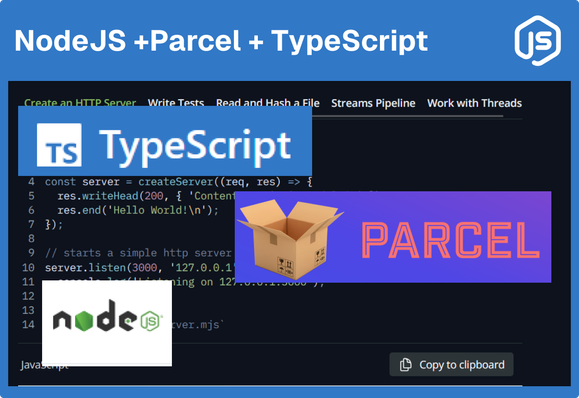
How to Set Up a Node.js Project with Parcel and TypeScript https://jsdev.space/howto/nodejs-parsel-ts/ #typescript #nodejs #parsel
Бенчмарк HTML парсеров в Python: сравнение скорости
Привет, Хабр! Меня зовут Вадим Москаленко и я разработчик инновационных технологий Страхового Дома ВСК. В этой статье хочу поделиться с вами информацией по проведенному сравнению производительности нескольких популярных библиотек для простого HTML-парсинга. При необходимости сбора данных с HTML или XML, многим python-разработчикам сразу вспомнятся две популярные библиотеки «BeautifulSoup4» и «lxml» — они весьма удобны и стали широко применяемыми. Но что, если в нашем проекте важна скорость сбора данных? Возникает вопрос: кто из них быстрее и есть ли еще более быстрые библиотеки? При поиске данной информации на Хабре, я нашел подобные статьи, но им уже несколько лет. Так как прогресс не стоит на месте и появляются новые инструменты или те, о которых еще не слышали, мне было интересно провести личное исследование и поделиться информацией. Ремарка: выбор библиотеки зависит от конкретных требований проекта, также существует еще множество инструментов, которые не были освещены в данной статье, к примеру «Scrapy» — это мощный асинхронный фреймворк. В исследовании акцентируется внимание на более простой задаче, поэтому я не гарантирую что лидер бенчмарка подойдет именно вам. Помните о важности проведения собственных тестов и анализа требований вашего проекта перед принятием решения. В качестве задачи используем поисковик нашего любого habr.com , в который отправим запрос с ключевыми словами «html parsing python» и соберем следующие данные по каждой статье: имя автора, заголовок, дату создания статьи, количество просмотров и голоса (оценки).
https://habr.com/ru/companies/vsk_insurance/articles/780500/
#benchmark #бенчмарк #html #parsing #python #beautifulsoup4 #lxml #parsel #requestshtml #selectolax

