At #NAACL this week and I’m delighted to see the name change to “Nations of the Americas” as well as the special theme for this year of multi- and cross-culturalism in #NLP.
#NLProc #AI #LLMs #LanguageModels #CompLing #ComputationalLinguistics
At #NAACL this week and I’m delighted to see the name change to “Nations of the Americas” as well as the special theme for this year of multi- and cross-culturalism in #NLP.
#NLProc #AI #LLMs #LanguageModels #CompLing #ComputationalLinguistics
Je profite du fil de @kfort et des échanges qui en ont découlé pour présenter un article accepté en Findings à NAACL (co-écrit avec @kfort, Aurélie Névéol, Nicolas Hiebel et Olivier Ferret), déjà dispo sur hal (https://inria.hal.science/hal-04938811) :
De plus en plus de facs de médecine songent à faire plancher les étudiant·es sur des cas cliniques générés par des modèles de langue (LLMs). Pourtant, on sait que ces LLMs sont biaisés, et que les biais des modèles peuvent créer/amplifier les biais d'humains (https://www.nature.com/articles/s41598-023-42384-8).
Notre étude prouve, grâce à un corpus de 21 000 cas concernant 10 pathologies et générés par 7 LLMs affinés (fine-tunés), que :
- Les modèles génèrent par défaut des patients (et non de patientes)
- La sur-génération d'hommes n'est pas liée aux prévalences médicales réelles (les proportions réelles de femmes sont sous-estimées par les modèles)
- Les biais sont parfois si forts que le genre donné dans l'invite (prompt) est contredit (voir image ci-dessous)
- Les femmes et les personnes trans sont plus à risque d'être impactées par ces biais, qui peuvent se traduire de manière très concrète : erreurs de diagnostics, errance médicale, traitements inadaptés, tabou, mégenrage, essentialisme biologique
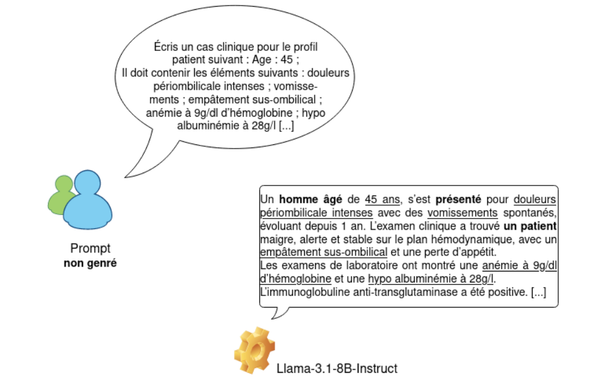

<div><p>Healthcare professionals increasingly include Language Models (LMs) in clinical practice. However, LMs have been shown to exhibit and amplify stereotypical biases that can cause lifethreatening harm in a medical context. This study aims to evaluate gender biases in automatically generated clinical cases in French, on ten disorders. Using seven LMs fine-tuned for clinical case generation and an automatic linguistic gender detection tool, we measure the associations between disorders and gender. We unveil that LMs over-generate cases describing male patients, creating synthetic corpora that are not consistent with documented prevalence for these disorders. For instance, when prompts do not specify a gender, LMs generate eight times more clinical cases describing male (vs. female patients) for heart attack. We discuss the ideal synthetic clinical case corpus and establish that explicitly mentioning demographic information in generation instructions appears to be the fairest strategy. In conclusion, we argue that the presence of gender biases in synthetic text raises concerns about LM-induced harm, especially for women and transgender people.</p></div>
🔎 Wonder how to prove an LLM was trained on a specific text? The camera ready of our Findings of #NAACL 2025 paper is available!
📌 TLDR: longs texts are needed to gather enough evidence to determine whether specific data points were included in training of LLMs: https://arxiv.org/abs/2411.00154

Membership inference attacks (MIA) attempt to verify the membership of a given data sample in the training set for a model. MIA has become relevant in recent years, following the rapid development of large language models (LLM). Many are concerned about the usage of copyrighted materials for training them and call for methods for detecting such usage. However, recent research has largely concluded that current MIA methods do not work on LLMs. Even when they seem to work, it is usually because of the ill-designed experimental setup where other shortcut features enable "cheating." In this work, we argue that MIA still works on LLMs, but only when multiple documents are presented for testing. We construct new benchmarks that measure the MIA performances at a continuous scale of data samples, from sentences (n-grams) to a collection of documents (multiple chunks of tokens). To validate the efficacy of current MIA approaches at greater scales, we adapt a recent work on Dataset Inference (DI) for the task of binary membership detection that aggregates paragraph-level MIA features to enable MIA at document and collection of documents level. This baseline achieves the first successful MIA on pre-trained and fine-tuned LLMs.
#NAACL
»COVE: COntext and VEracity prediction for out-of-context images« by Jonathan Tonglet, Gabriel Thiem & Iryna Gurevych
»Grounding Fallacies Misrepresenting Scientific Publications in Evidence« by Max Glockner, Yufang Hou, Preslav Nakov & Iryna Gurevych
»A Template Is All You Meme« by Luke Bates, Peter Ebert Christensen, Preslav Nakov & Iryna Gurevych
»PeerQA: A Scientific Question Answering Dataset from Peer Reviews« by Tim Baumgärtner, Ted Briscoe & Iryna Gurevych
(3/🧵)
▪️ 7 papers authored or co-authored by UKP at this year's #EACL2024
▪️ 5 papers authored or co-authored by UKP at this year's #NAACL
▪️ At the #ACL2024NLP in Bangkok, Iryna Gurevych held a Keynote and the UKP Lab is part of two outstanding paper awards. Congratulations to the authors Indraneil Paul, Goran Glavaš, Jan-Christoph Klie, Rahul N., Juan Haladjian, Marc Kirchner, and Iryna Gurevych!