Self-Distillation
Discover how self-distillation enables continual learning with minimal overhead

Self-Distillation
Discover how self-distillation enables continual learning with minimal overhead
Self-Distillation Enables Continual Learning [PDF]
https://arxiv.org/abs/2601.19897
#HackerNews #SelfDistillation #ContinualLearning #MachineLearning #AIResearch #PDF

Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
Our partners from CeADAR Ireland published a new paper on Continual Learning in the #CloudEdgeIoT Continuum. It explores how adaptive #AI can address concept drift, dynamic data & resource constraints.
This is key for enabling efficient, trustworthy AI & MetaOS orchestration across @O_CEI_Horizon ecosystem.
📑 Read the paper: https://o-cei.eu/wp-content/uploads/2026/03/Paper-CeADAR-Jan-2026-ICP.000586-3-2.pdf
📰 Discover O-CEI publications: https://o-cei.eu/scientific-publications/

AI 에이전트가 스스로 진화하는 3가지 방식, 모델 교체만이 답이 아니다
AI 에이전트의 학습은 모델 업데이트만이 아닙니다. LangChain이 제시한 모델·하네스·컨텍스트 3레이어 프레임워크를 소개합니다.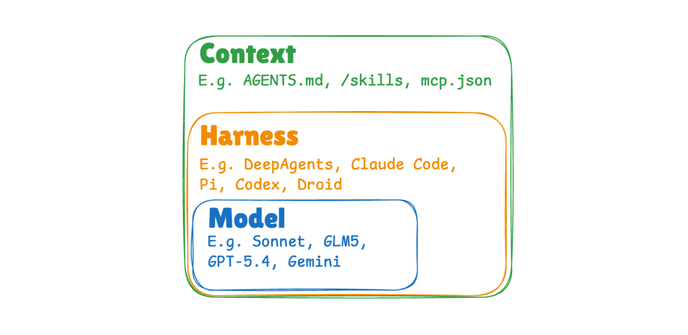
Liên tục học (Continual Learning) trong AI 2026 thực sự nghĩa là gì? Cập nhật trọng số mô hình theo thời gian thật hay chỉ là hệ thống bộ nhớ ngoài + huấn luyện định kỳ? Mô hình như Opus 5.0 có được vá liên tục? Hay kiến trúc chỉ là retrieval + làm mịn offline? Phân biệt giữa "học thực sự" và "nhớ + cập nhật phần mềm" là then chốt cho tiến tới AGI. #ContinualLearning #AI #MachineLearning #TríTuệNhânTạo #HọcMáy #AGI
https://www.reddit.com/r/singularity/comments/1q6attw/continual_learning_in_2026
Dự đoán: Bước đầu tiên của học tập liên tục sẽ thông qua tự nhắc nhở siêu cấp với RLMs. Các kỹ thuật prompt như CoT từng cải thiện suy luận; nay RLMs có thể mở rộng học trong ngữ cảnh thành dài hạn, liên tục. Prime Intellect đang nghiên cứu hướng này – có thể là bước đột phá tiếp theo sau CoT. #ContinualLearning #RLMs #AI #MachineLearning #Học_liên_tục #Trí_tuệ_nhân_tạo #AI_cao_cấp
New research shows Nested Learning’s Continuum Memory System lets AI bridge short‑term cues and long‑term understanding, building richer world models without catastrophic forgetting. A leap for continual learning and open‑source AI. Dive in! #NestedLearning #ContinuumMemory #ContinualLearning #WorldModels
🔗 https://aidailypost.com/news/nested-learnings-continuum-memory-system-redefines-ai-memory-2026

Nhân viên Anthropic dự đoán Continual Learning sẽ "được giải quyết một cách hài lòng" vào năm 2026. #ContinualLearning #HọcTậpLiênTục #TríTuệNhânTạo #AI #Anthropic #Year2026 #Năm2026 #MachineLearning #HọcMáy
https://www.reddit.com/r/singularity/comments/1pu9pof/anthropics_sholto_douglas_predicts_continual/