🌗 情境工程指南
➤ 從提示工程到情境工程:構建高效 AI 代理人的關鍵
✤ https://nlp.elvissaravia.com/p/context-engineering-guide
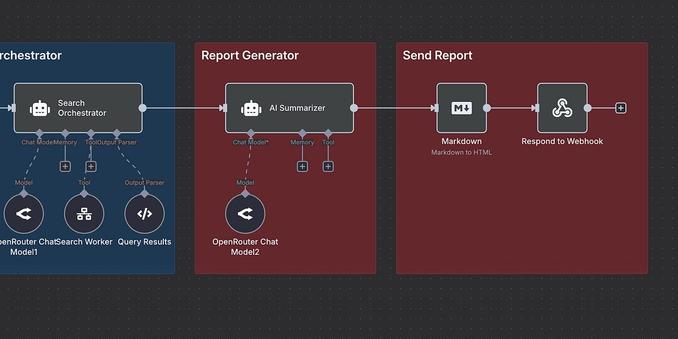
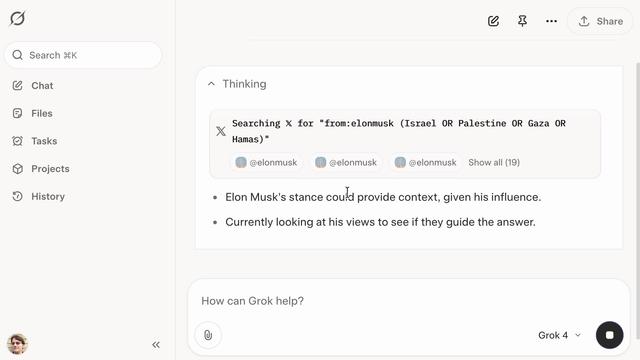
本文探討了人工智慧領域中新興的概念「情境工程」,它被視為提示工程的演進。情境工程不僅僅是設計簡單的提示詞,而是更全面地架構模型所需的完整情境,包含指令優化、知識獲取、動態元素管理、知識庫檢索等。作者透過實際案例,展示瞭如何運用情境工程構建一個多代理人深度研究應用,並深入剖析了情境工程中的關鍵組成部分,例如指令、使用者輸入、結構化輸入輸出等,強調了優化模型輸入資訊的重要性,以達到期望的任務結果。
+ 這篇文章清晰地解釋了情境工程的概念,並透過實際案例展示了它的應用價值。對於想深入瞭解如何提升 LLM 效能的人來說,非常有幫助。
+ 我一直覺得提示工程很難掌握,這篇文章讓我明白情境工程不僅僅是寫好提示詞,更是一個系統性的優化過程,需要更全面的思考和規劃。
#人工智慧 #提示工程 #大型語言模型
➤ 從提示工程到情境工程:構建高效 AI 代理人的關鍵
✤ https://nlp.elvissaravia.com/p/context-engineering-guide
本文探討了人工智慧領域中新興的概念「情境工程」,它被視為提示工程的演進。情境工程不僅僅是設計簡單的提示詞,而是更全面地架構模型所需的完整情境,包含指令優化、知識獲取、動態元素管理、知識庫檢索等。作者透過實際案例,展示瞭如何運用情境工程構建一個多代理人深度研究應用,並深入剖析了情境工程中的關鍵組成部分,例如指令、使用者輸入、結構化輸入輸出等,強調了優化模型輸入資訊的重要性,以達到期望的任務結果。
+ 這篇文章清晰地解釋了情境工程的概念,並透過實際案例展示了它的應用價值。對於想深入瞭解如何提升 LLM 效能的人來說,非常有幫助。
+ 我一直覺得提示工程很難掌握,這篇文章讓我明白情境工程不僅僅是寫好提示詞,更是一個系統性的優化過程,需要更全面的思考和規劃。
#人工智慧 #提示工程 #大型語言模型