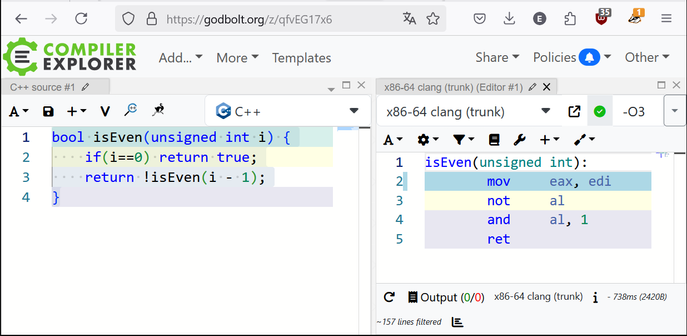
@NanoRaptor that’s pretty good for a stream of thought. Perhaps try some more with other Spielberg movies, or some James Cameron?
Financial Services System Engineering. Author.
| Website | https://juliangamble.com/ |

| Website | https://juliangamble.com/ |
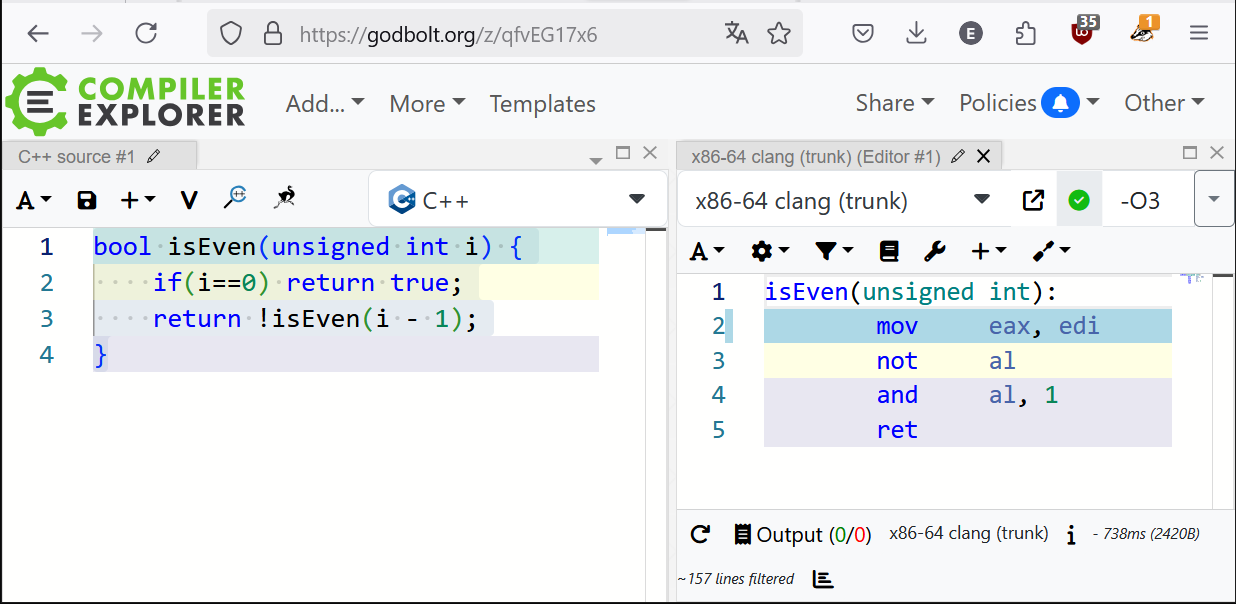
@viduq @ela Check out how examples like this are also reduced to simple polynomials without loops:
https://godbolt.org/z/cze5Y1b7j
The -1431655764 is pretty fiendish if you've not met that trick before.
@ela ah whelp u answered this while I was typing :'D
@viduq@mstdn.social It's not exactly brute force, but it does involve some heavy lifting in the optimizer. Tail recursion elimination turns the recursive calls into a loop. Then, induction variables of the loop are detected, and finally strength reduction, algebraic simplification finish it off.
Actually, this is what bad code writing looks like.
@gilesgoat @ela, it's not “i % 2”, as that would give an inverted result. It's either “~i & 1” or “1 & ~i”, depending on the output assembly code. Here it is, for 32-bit ARM:
MOV r1, #1
BIC r0, r1, r0
BX lr
(BIC is bit-clear, essentially AND NOT.)
@nrab @porglezomp LLVM extends that basic algorithm a tad bit by trying to move instructions between the call and the return to the top of the generated loop. In cases in which this isn't trivially true (like for code neither depending on the function call value nor having an influence on the return value), there is one additional trick. If the operation performed on the return value of the function call is a commutative and associative operation, it can be eliminated using accumulator recursion elimination.
The code lives here: https://github.com/llvm/llvm-project/blob/main/llvm/lib/Transforms/Scalar/TailRecursionElimination.cpp#L658
@josch This code snipped has been floating around for a while, here's a blog post from a few years ago talking about it that seems to be the original source: https://www.notion.so/mjbo/Exploring-Clang-LLVM-optimization-on-programming-horror-acd2bb52dd934d9c9a76150484f3b64f
Credit them. :)
IndVarSimplifyPass llvm optimizer pass, and the math for that is implemented in ScalarEvolutionExpander.cpp@ela This is quite impressive, and I wonder how complex you could make these kinds of functions while still having this kind of optimisation happening.
But it does make me ask: Should perhaps the compiler warn about these cases? I mean, it's great that the compiler can optimise it, but when it can, the code should probably be simplified, and that would be better than relying on the compiler.
@loke The problem here is that the compiler can't tell if something is just an idiomatic expression or bad coding. In fact, such warnings might even distract programmers from getting things right.
It's very important to keep in mind that source code has a dual purpose. Yes, it instructs the computer what to do, but computers are perfectly fine with machine instructions. Much more importantly, source code exists for humans to read, understand and reason about.
Premature optimization is the root of all evil. The primary goals of writing code must be correctness and readability, with correctness often being influenced by readability.
Sure, some code needs to be super fast. Your interrupt handler for that 10GB network card? This code doing the task switching in your OS? Absolutely. Every cycle counts. But in order to achieve this, you need to measure. I've seen a lot of theories about performance improvements collide hard with the realities of modern CPU and compiler architecture. Always profile, always measure, always benchmark.
And for that precious lines of code, modern compilers are happy to infodump on you every step they take.
@ela @loke There's a lot of examples of this. Like mergesort vs quicksort (yes, no one uses vanilla quicksort but I would argue that it's closer to quick than merge). And then in network science you have these algorithms where runtime is around cubic and whether quadratic, cubic or tertiary is the right choice very much depends on the properties of your graph, like actual size, rather than what happens when n goes towards infinite.
Edit: urgh, I'm being a reply guy. Sorry. Graphs are neat.