When you saw a mafia attack another, it's not because of they care about democracy, rule of law, or welfare of the people, but about their own power.

Earthwalker
@earthwalker
- 4 Followers
- 15 Following
- 134 Posts
Vegan.
We call Earth a village. To measure any true achievement, we should evaluate on the Earth level. If it's only valid on personal, national, or even humanity level, but fail at the Earth level, then it's not a true achievement.

Maintaining Peaceful Societies w/ Douglas Fry
Be aware
Hell fire raining from Israel
Will returns to Israel
Be aware
He who dances with the devil
Will rot in hell
Hell fire raining from Israel
Will returns to Israel
Be aware
He who dances with the devil
Will rot in hell
To see the reality as is
https://www.youtube.com/watch?v=Jq6seKNEahU
https://www.youtube.com/watch?v=Jq6seKNEahU

EP 51 - Vali Nasr: Iran's Grand Strategy: A Political History
Treasure of Wisdom
https://vandanashivamovie.com
https://vandanashivamovie.com

It'll be interesting how US handle it's current crisis
https://www.youtube.com/watch?v=TMyHbgUYk78
https://www.youtube.com/watch?v=TMyHbgUYk78

Timothy Snyder: The New Paganism—A Framework for Understanding Our Politics | LIVE from NYPL
Started a side project Speak, a education oriented TTS inference server. It's using model Spark-TTS at this moment, supports voice clone, streaming, long text.
Project Conscious has added feature flashcard with the FSRS algorithm, and integrated the Speak API to support multi-speaker speech. You can now listen to your flashcard with as many type of voices as you need.
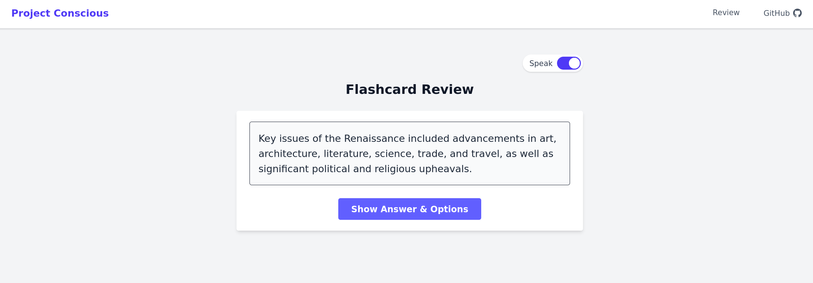

Started a new open-source project: Conscious (https://github.com/ittia-research/conscious).
To explore interfaces between AI and human, memory system and sharing.
Welcome to join the discussions: https://github.com/ittia-research/conscious/discussions
#memory #conscious #AI #LLM
To explore interfaces between AI and human, memory system and sharing.
Welcome to join the discussions: https://github.com/ittia-research/conscious/discussions
#memory #conscious #AI #LLM

People was talking about shit, now eating shit.