An illusion of predictability in scientific results: Even experts confuse inferential uncertainty and outcome variability
https://doi.org/10.1073/pnas.2302491120
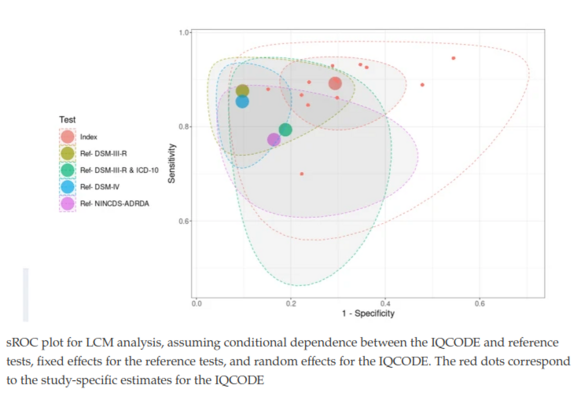
Visualizing only inferential uncertainty can lead to significant overestimates of treatment effects, even among highly trained experts
Solution: when possible, plot individual data points alongside statistical estimates