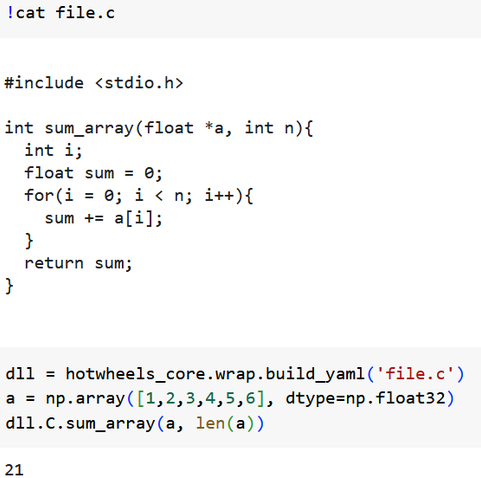
Do you have a numerical simulation and need to compute the gravitational potential of a cosmological simulation? hotwheels Particle-Mesh OpenMP+MPI stand-alone module (inspired by Gadget2,4) can do it easily and is integrated with Python wrappers too!