

Co-Founder/CTO @pirateship
#engineering #php #aws #react #hamburg #nobullshit #love #fedi22
| pirateship.com | pirateship.com |

Co-Founder/CTO @pirateship
#engineering #php #aws #react #hamburg #nobullshit #love #fedi22
| pirateship.com | pirateship.com |
I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
Huge respect for the EU Commission, @EUCommission, who have updated their webpage with a new follow button — X is out, Mastodon is in!
Remember to reward them with a follow! ♥️🇪🇺
Seen here: https://commission.europa.eu/index_en

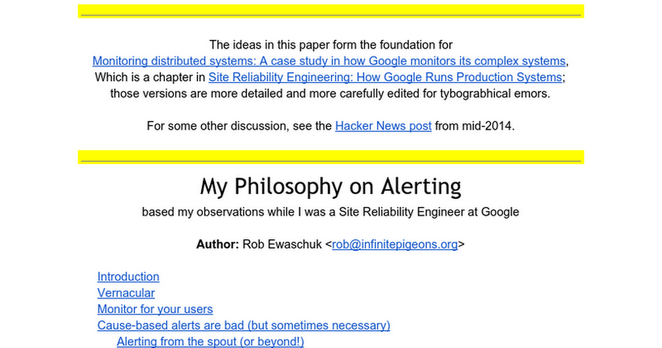
Alerting ist eins dieser Felder, bei denen viele nur auf Technik schauen. Mehr Metriken, mehr Regeln, mehr Conditions. Und dann wundert man sich über flapping Alerts und genervte Oncall-Teams.
"My Philosophy on Alerting" ist genau deshalb so gut, weil der Text auch den kulturellen Teil ernst nimmt: Wie denkt ein Team überhaupt über Alerts?
Lesenswert: https://docs.google.com/document/d/199PqyG3UsyXlwieHaqbGiWVa8eMWi8zzAn0YfcApr8Q/edit?tab=t.0
Today on "can't make this shit up":
I've been in a German hospital for a few weeks. For every meal we get to pick from three options. My hospital roomie picked "fish and chips".
Lo and behold:

A COMPUTER CANNOT FIND OUT
THEREFORE A COMPUTER MUST NEVER BE ALLOWED TO FUCK AROUND
#Product Model = customer-focus and standard offerings
If you are just customer focused but don’t have standard offerings, you’re essentially in a consulting model. Consulting models only scale with more people.
Standard offerings (aka Paved Paths, Golden Paths) enable scaling through technology.
Impact vs labor cost graphs for consulting models look like parallel lines (in the best case). With product models, the lines diverge. impact grows faster than headcount.

