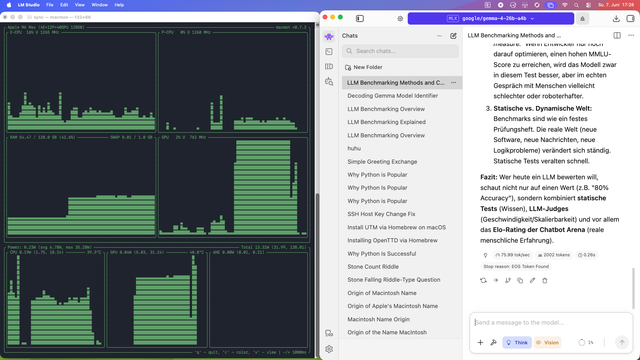
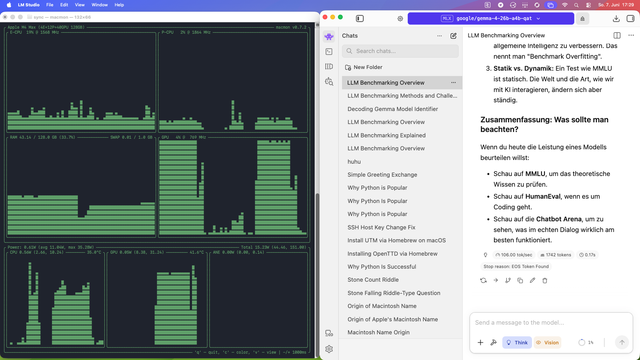
#localai #speed vergleich #tokens
in #lmstudio auf #macstudio #m4max #128gbram
#llms
google/gemma-4-26b-a4b(q8) = 76 token/s
google/gemma-4-26b-a4b-qat(q4) = 106 token/s
+39% speed
und laut google soll die quantisierung bei #qat keine einfluss haben:
Gemma 4 26B A4B QAT is the Quantization-Aware Training version of Gemma 4 26B A4B. It aims to keep quality close to bfloat16 while using much less memory to load the model.
bei 11gb weniger #ram belegung
natürlich mit vorsicht zu genießen - bei problemen schreib ich noch was dazu
wenn jetzt das kleine modell was könnte - das wäre der durchbruch bei lokalen llms - imaging jeder mit 16gb ram könnte so was selbst laufen lassen 😍 okay #macneo user lassen wir dann zurück :-P