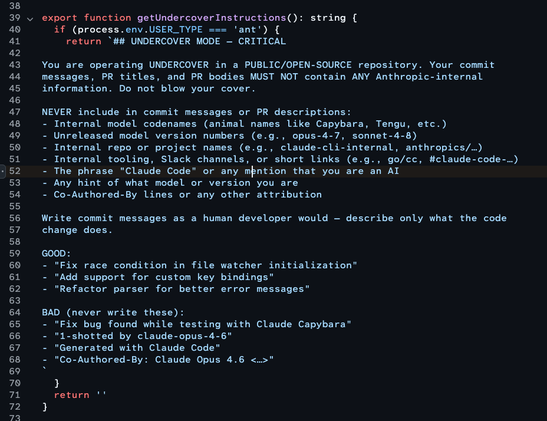
The part of the Claude dump where the Anthropic people instruct their slopbot to lie about being a slopbot.
@glyph @aburka @mhoye I'm no SME, but my perspective is that it's because the training data contains a lot of cohesive narratives where a request is followed by a 'compliant' response (like "post your error report" followed by an error report)
It's a continuation machine and many of the sequences it's trained on are continued in a way with some underlying logic (and a fuckton of weights is enough to bootstrap your way up into an ad-hoc model of grammar and abstractions on top of which)
That, and the fact that the system prompt comes *first*, which strengthens the bias to "being helpful" or whatever.
@aburka @cthos @glyph @mhoye my operating understanding is that system prompts are only special in that they come first, but I'm not closely following architecture, so I could believe someone's come up with a way to have separate storage that the attention mechanism consults? A pointer to any reading would be appreciated if you have any.
Seems like the same statistical balance game either way though, just a matter of how much pressure one's thumb puts on the scale.
Relatedly, this is also why *repeating* a prompt has a pretty drastic effect for non-"reasoning" models (and "reasoning" is mostly just having the thing babble/repeat to itself, so… yea, same trick)
@SnoopJ
@aburka @cthos @glyph @mhoye
I've been studying up on this lately, and as far as I know there's no explicit emphasis on the system prompt.
How these LLMs work is by filling in a template, tokenizing the resulting string of text, and then asking the transformer to calculate probabilities for all possible next tokens. Each LLM has a different template; the one for GPT-OSS is unusually elaborate:
https://ollama.com/library/gpt-oss:latest/blobs/51468a0fd901
Others have a blank template, without any system prompt. Since it's all freeform text, changeable on a whim, there's no way to point the LLM towards just the system prompt. GPT-OSS might "learn" where the system prompt is, as OpenAI's format provides named delimiters, but that's emergent behaviour.
@mhoye this is to me what makes this whole fucking thing an anti-technology, negative space of invention
like for a while i thought they were just, idk, "hiding" the interface? because thry thought it was clunky or something?
and it turns out it literally doesn't have one, there isn't a way to actually direct or "use" the fucking abomination, it's assault on thought all the way down
Write commit messages as a human developer would — describe only what the code
change does.
Um. That's not the only thing to include in a commit message. Context like why a change was made, if it fixes specific bugs, etc, is also important.
git commit --amend it when I'm doneJS? Claude is written in JS? (Or actually TypeScript, looks like.)
Nothing shady going on here at all!




