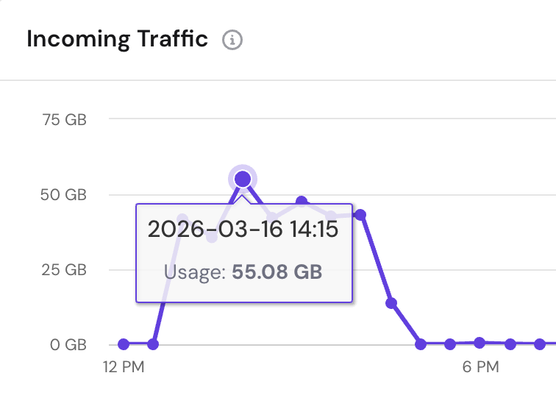
Yesterday my VPS set off a warning, as it was hit by a huge spike in incoming traffic, peaking at 55GB at 2:15pm and lasting for an hour.
Upon investigating, it turns out it was my PeerTube instance that was targeted.
Where did the traffic come from?
meta-externalagent (aka Meta's web crawler which is used to grab content to train its AI system).
I feel a little bit violated thinking my Fediverse promo video was grabbed by it, sigh.