One of the ways that LLM-authored code improves productivity is by merely SAYING it does things. It's way faster than the whole time-consuming process of actually doing things. This is real code someone sent to me for review.

Here is a way that I think #LLMs and #GenAI are generally a force against innovation, especially as they get used more and more.
TL;DR: 3 years ago is a long time, and techniques that old are the most popular in the training data. If a company like Google, AWS, or Azure replaces an established API or a runtime with a new API or runtime, a bunch of LLM-generated code will break. The people vibe code won't be able to fix the problem because nearly zero data exists in the training data set that references the new API/runtime. The LLMs will not generate correct code easily, and they will constantly be trying to edit code back to how it was done before.
This will create pressure on tech companies to keep old APIs and things running, because of the huge impact it will have to do something new (that LLMs don't have in their training data). See below for an even more subtle way this will manifest.
I am showcasing (only the most egregious) bullshit that the junior developer accepted from the #LLM, The LLM used out-of-date techniques all over the place. It was using:
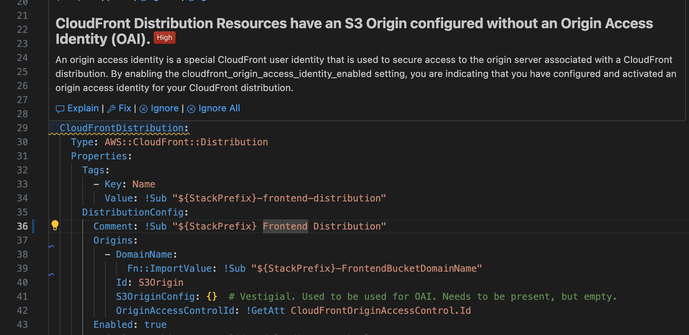
So I'm working on this dogforsaken codebase and I converted it to the new OAC mechanism from the out of date OAI. What does my (imposed by the company) AI-powered security guidance tell me? "This is a high priority finding. You should use OAI."
So it is encouraging me to do the wrong thing and saying it's high priority.
It's worth noting that when I got the code base and it had OAI active, Python 3.9, and NodeJS 18, I got no warnings about these things. Three years ago that was state of the art.
It is even worse than that, there will be a rush by folks looking to poison the data set to plant enough bad code w/ exploits they know about in the hopes that it gets seeded in some x% of code bases given them plenty of low hanging fruit to pick.
I'd be interested to know whether the models make any effort to distinguish working code from non-working code (in StackExchange, etc.). So many threads have the form: 1) Here is some code I wrote - why doesn't it work? 2) Lots of snippets and suggestions, but no integrated working version.
Not interested enough to investigate. I will have nothing to do with "AI" code.
They are purely statistical inference, there is no notion of understanding good or bad code.
What is the saying they tell little kids in daycare, "you get what you get and you don't get upset"
This is why there are all sort of tricks like writing a lot of tests and having detailed specifications. This "should" catch a lot of these obvious problems.
This does not guarantee the code is maintainable or that the code is not fragile or that the code is not some mismash of different idioms that don't mesh well.
I guess a approach would be to hand curate some enormous repository of super high quality code but this is a rightfully hard problem, if we could do this reliably at scale then all out problems would be solved and we wouldn't need all the tools we have.
Thanks for the reply - I fully understand this. I am a 40-year-career software engineer who can't imagine a situation in which I would want to replace my coding with statistically likely code-resembling text generation.
But I'm intrigued as a mental exercise by imagining someone 1) who thought this was a good idea and 2) who wanted to leverage useful information from examples in StackExchange-like discussions and 3) who was actually careful about what they were doing.
How would such a person go about filtering such examples to extract just those that seem to be working for some purpose? This is just one small aspect of the pre-training work that ought to have happened and that, I'm guessing, was skipped on the assumption that the errors would be swamped by the volume of examples.
The two most recent examples I've had of searching for useful code snippets on the web (one for reading a particular GPS sensor from Python, the other for a messy case of generating JavaScript code from PHP) both took me to multiple online examples, and in all cases, the only complete end-to-end code was the failing one submitted by the OP. So, blindly consuming all available examples would be disastrous.
If you reduce the training data only to the final most-upvoted replies that actually containing code blocks, the volume of this kind of training data on the web drops dramatically.
The largest other category of hopefully functioning online code (git repositories, etc.) tends to lack the contextual labeling ("How do I ... ?") that would make it good for code chatbottery of the "Build me a system that does X" kind.
The biggest frustration I have with the whole LLM/chatbot onslaught (well, the biggest other than the billionaire oligarch sociopathy of it all) is that it deliberately obfuscates the decomposition of big challenges into what can only realistically be being solved with the help of non-LLM modules. Knowing how those modules are being leveraged would make it so much easier to estimate the likely categories of error.