Sehr schöner ChatGPT Takedown an einem sehr simplen aber extrem lustigen Beispiel https://mindmatters.ai/2025/08/chatgpt-5-tries-out-rotated-tic-tac-toe-you-be-the-judge/



@rstockm Abgesehen davon, dass ich so eine „aber dieses 0.0.1 Update ändert alles“ Argumentstion sehr dünn finde. ChatGPT 5.2 ist kaum mehr als ein marketing Update über 5.0, es ändert nichts daran wie diese Modelle funktionieren und ändern somit auch nichts an der fundamentalen Kritik selbst wenn die neue Version bei dem konkreten Beispiel vielleicht marginal besser abschneidet.
@343max Na ja, es ist aber halt andersrum: dieses „Beispiel" funktioniert bei exakt KEINEM der aktuellen Flagship-Modelle. Getestet: Mistral (lokal!), Gemini 3 Pro, ChatGPT 5.2, Claude Sonnet 4.5.
Keines fällt darauf rein, die Antwort von Gemini mal als hübsches Beispiel.
Und so läuft das seit 2 Jahren:
10 „haha, schaut was die GPTs alles nicht können"
20 ich setze mich 1 Minute dran und exakt das funktioniert in allen neuen Modellen
30 goto 10
🤷🏻♂️

@rstockm Aber ich habe dir doch eben einen Screenshot geschickt wie das aktuelle ChatGPT genau darauf reinfällt.
Für mich ist es exakt andersrum wie du beschreibst. Seit Jahren:
10 du und andere AI believer: “ja, noch vor ein paar Wochen war das Modell noch strunzdumm, aber heute können sie exakt dieses eine Beispiel lösen, darum sind sie perfekt”
20 jemand findet ein neues Beispiel wie ein "Flagship-Model" haarstäubend dumme weise auf die Fresse fällt… (1/2)
30 die AI Firmen bringen neue Modelle raus die auf exakt diesen Fall nicht mehr reinfallen
40 goto 10
le sigh
Wir haben exakt die selbe Diskussion schon diverse Male geführt. Was bringt dich auf die Idee das ChatGPT 5.2.4 Code Red Edition dieses mal aber wirklich all die Versprechen einlöst, die all die anderen Versionen nicht einlösen konnten? (2/2)
@343max Ich rede nicht von ChatGPT sondern generell von den rechts unten Modellen, auch der anderen Hersteller. Bei deinen Screenshot kann ich nicht sehen, welches das ist. Das mit Abstand beste Besispiel das du bisher hattest war das Zahlenraten-Spiel, weil es so hübsch die Schwäche von LLM (will alles könne) mit den Limitierungen (unfähig, eigene Grenzen zu erkennen) exploited hat. 1/2
@343max Aber auch dort habe ich in 20 Minuten einen Weg gefunden (dank KI) um dieses Spiel auf beliebigen LLMs zu 100% perfect „ready to ship“ laufen zu lassen.
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
Und darum geht es mir: mir gehen wirklich die Szenarien aus, wo LLMs mit etwas Tuning, RAG Modellen etc. _nicht_ zu "ready to ship" zu bringen sind. Da ist mir dann AGI ziemlich egal.
Gemini 3 Pro kann meine Handschrift lesen, und zwar perfekt. das schaffen 99% der Menschen um mich herum nicht - was für eine Basis für Automatisierung!
@rstockm Das Beispiel mit dem Zahlenratespiel gilt exakt so noch heute. Das eine LLM so ein Zahlenratespiel in Software gießen kann war nicht die Aufgabe, das ist trivial für eine LLM weil es dafür Millionen Codebeispiele gibt. “Ja, es kann das nicht aber dafür kann es was anderes” ist keine Lösung des Originalproblems.
@343max Oh das war ohne Software, nur über einen Prompt.

@rstockm Exakt. Du lässt die AI ein anderes Problem lösen als das was ich ihr gegeben hatte. Was ist damit bewiesen außer das es andere Probleme möglicherweise lösen kann. (Ich bezweifle übrigens nach wie vor, dass dein Beispiel besser funktioniert als meins, du hast es einfach nur viel komplexer gemacht, was es mühseliger macht die Schwächen zu finden. Abgesehen davon, dass es ein komplett anderer Prompt ist)
@343max Das ist mir als Produktmanager aber doch völlig egal. Es ist "ready to ship“, das zählt. Und es kann ja ausprobiert werden - funktioniert wunderbar und 100% zuverlässig.
@rstockm Aber MIR ist es nicht egal. MIR ist es schon wichtig, dass eine AI ein sehr einfaches Problem das jeder Mensch problemlos lösen kann von dem die AI behauptet es lösen zu können dann auch lösen kann. Ich habe dieses Beispiel gewählt, weil es sehr anschaulich macht, wie die AI es einfach per Design nicht kann.
@rstockm Du sagt “aber es kann ein komplett anderes Problem lösen und das reicht mir”. Okay. Aber stimmst du mir zu, dass es das eigentliche von mir beschriebene Problem nach wie vor nicht lösen kann?
@343max Ich glaube in der Sache sind wir gar nicht weit auseinander, wir haben nur sehr unterschiedliche Perspektiven auf die Grundfrage. These:
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
1)
Ralf: zentral ist, dass ein Problem verlässlich mit LLM gelöst werden kann. Egal wie der Weg ist.
Max: zentral ist: dass auch der komplette Weg vom LLM perfekt gegangen wird ohne Begleitung
2)
Ralf: nutzt ausschließlich die besten für Geld verfügbaren Modelle, ignoriert den Rest
Max: nutzt was gerade da ist, auch die freien Versionen
Die prinzipiellen Schwächen dieser Systeme ignoriert er oder erzählt mir das wenn ich nur wohlhabender wäre und 200€/Monat Abos hätte alles total toll wäre (kann ich halt nicht überprüfen und scheint mir auch nicht glaubhaft) (2/2)
@343max Das Schöne ist ja, dass es Forschung gibt und die ist bisher ziemlich eindeutig. Man fühlt sich als Softwareentwickler mit LLM-"Unterstützung " deutlich produktiver als man tatsächlich ist.

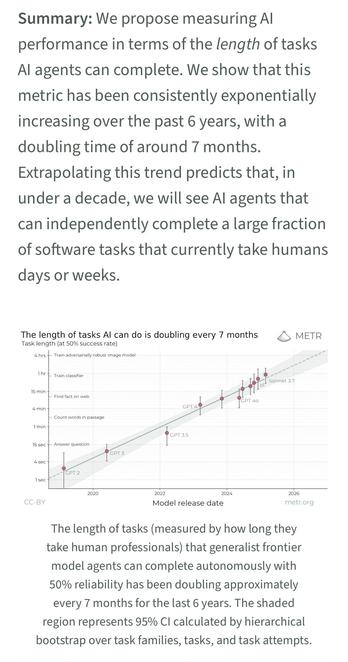
@rstockm @343max 2020 ist nicht ganz 10 Jahre her. Und ja, ich habe das Gefühl, dass es in den letzten 1-2 Jahren eher eine Stagnation gibt
@rstockm @343max Bisher hat mich noch kein LLM für die Softwareentwicklung überzeugt. Ja, die kotzen schnell einen Prototypen raus, aber sobald die echte Welt damit in Verbindung kommt, explodiert alles.
Für kleine Nischenprobleme kann es vielleicht was taugen, aber da sind spezielle Lösungen sicher besser als LLMs.
@lbenedix @343max Alles hier aus den letzten 2 Jahren dazu zwei nicht öffentliche die noch komplexer sind:
https://github.com/rstockm?tab=repositories
Es kommt halt auch darauf an ob man die LLMs beim Coden als Gegner sieht den man aufs Kreuz legen möchte oder als endlos geduldig motivierten Junior DEV den man ins eigene Projekt einarbeitet.

@343max @rstockm Bei der Beurteilung, ob ein LLM gute Arbeit macht, spielen viele psychologische Verzerrungen mit. Es fängt schon damit an, dass man selbst etwas tut, also einen Prompt formuliert und dann passiert etwas. Das ist natürlich toll.
Aber ja, es gibt glaub ich kein erfolgreiches Open Source Projekt, bei dem der überwiegende Anteil der Contributions von LLMs kommt. Oder?
@lbenedix @343max Schön, dass ihr euch einig seid, dass meine Apps alle unterkomplex sind. Was ich sagen kann:
1) ich habe keine Zeile davon selbst geschrieben
2) keines der Projekte hätte ich angefangen ohne LLMs (ich kann kein JavaScript)
3) die Oneshot Quote ist mit den Monaten kontinuierlich gestiegen, bei Testabend fast alles bis auf mobil CSS
4) Einigen der Tools würde ich doch gesellschaftlichen Nutzen zuschreiben wie Mastowall, Mastotags oder Fedipol.
1) ich habe keine Zeile davon selbst geschrieben
2) keines der Projekte hätte ich angefangen ohne LLMs (ich kann kein JavaScript)
3) die Oneshot Quote ist mit den Monaten kontinuierlich gestiegen, bei Testabend fast alles bis auf mobil CSS
4) Einigen der Tools würde ich doch gesellschaftlichen Nutzen zuschreiben wie Mastowall, Mastotags oder Fedipol.
@rstockm Geht mir genauso. Ich brauchte zB Backup-Apps für ein phpBB Forum und meine Friendica-Instanz. Ersteres hab ich vor Jahren schon mal selbst gemacht. War ein Mega-Gefummel und ich hab nichts sinnvolles dabei gelernt.
Mit Claude ging das nicht nur schneller, sondern ich habe auch reichlich gelernt, wie Dinge mit Python gehen können, ohne mich erst durch hunderte Packages zu wühlen, oder in CSS, wo ich so überhaupt keine Ahnung habe. (Die Backup-Apps können static web sites mit den Inhalten erzeugen)
Ich habe aber reichlich Erfahrung in Specs schreiben, Leute anleiten und deren Zeugs testen und debuggen. Job-mässig bin ich eher in C/C++ für Produktionssteuerungen unterwegs. Von embedded bis SAP-Anschluss.
Ich mag die Geschwindigkeit, wenn ich mit Coding LLMs werkel. Es lassen sich Dinge ausprobieren, wo ich Stunden für's (um)schreiben gebraucht hätte. Ich kann viel schneller Packages und Libs finden und anwenden (lassen) in Bereichen, wo ich mich bisher nicht auskenne. Beim Friendica-Backup zB die Authentification, die vier web-APIs, usw. Ich die meiste Zeit auf der funktionalen Ebene, nicht mit einzelnen Fizzeligkeiten beschäftigt. Claude kann inzwischen auch ziemlich gute Doku und Kommentare schreiben, so dass ich mich auch in Code unbekannter Sprachen schnell zurecht finden kann, wenn ich mal genauer schauen möchte.
Libraries/Frameworks, Schönes Beispiel, ja …
Ich fang in Cursor damit an das mit ein llm erstmal eine spec und Architektur und requirements schreibt, aus einem offenen Brainstorming mit dem Agenten. Da gehört auch dazu, die Frage zu klären welche libraries/Frameworks man für bestimmte Aspekte nutzen kann und welch pro und con es gibt. Wenn ich dann angebe dass ich kein Enterprise ready riesenframework brauche sondern genau einen Aspekt betrachtet und gelöst haben will, dann kann mir das llm verschiedene Optionen vorschlagen, inkl
Selbstschreiben, und ich kann dann als Architekt das Vorgehen bestimmen.
Am Ende giest der Agent das Brainstorming in die beiden Files Requirements.md und Techspec.md und das sind die ersten Files im Git Repo.
Meine Cursor-Rules sagen, dass diese beiden Files immer wieder Teil des Context sind und zu beachten sind.
natürlich können die sich in den nachfolgenden Sessions auch noch angepasst werden … neue offene Fragen werden dort erörtert und beantwortet.
Ein anderer Agent erstellt dann aus diesen Files einen Plan zum abarbeiten und erst die dritte Agent-Session erzeugt überhaupt Code und trackt den Fortschritt im Plan.
Ja, das ist kein OneShot… das ist den Juniordev an die Hand nehmen und ihm logische Planung abnehmen.
Man kann den Junior DEV benutzen und mit ihm produktiv sein. Man kann sich so verhalten, dass man dem juniodev die ganze Zeit Rätsel gibt, die die graue Emminenz kennt und dem Junior dann vor dem Kopf knallen, wie doof er ist. Ich bin gespannt wie lange das im reallife gut geht.
Ralph hat oben mwn nicht behauptet dass die llms alle auf architektenlevel arbeiten. das ist es aber was viele aufgrund des Hypes da rein interpretieren.
Nein! das sind erstmal dumme Juniors die nur bis zur nächsten Frage denken können und wenn man ihnen nicht genug Context gibt, bzw nicht weiß wie man das macht, der ist enttäuscht…
Sorry for the longread, my 2ct
@jwalzer @rstockm Genau so arbeite ich auch. Bei größeren Projekten auch mit Projektplan und Meilensteinen, die ich den Agent erstellen und pflegen lasse, die ich aber prüfe und abändere, bevor ich das Go gebe.
Kleinschrittiges Arbeiten scheint bei mir nötig, um Limits und Degradation zu vermeiden.
Die Pläne und Doku sind auch nötig, um zu archivieren und irgendwann später wieder aufsetzen zu können. Es ist schon erstaunlich was bei „erstelle eine vollständige Doku mit Spezifikationen, Entscheidungen und Erkenntnissen, um später in einem neuen Chat fortsetzen zu können" alles entsteht.
Kleinschrittiges Arbeiten scheint bei mir nötig, um Limits und Degradation zu vermeiden.
Die Pläne und Doku sind auch nötig, um zu archivieren und irgendwann später wieder aufsetzen zu können. Es ist schon erstaunlich was bei „erstelle eine vollständige Doku mit Spezifikationen, Entscheidungen und Erkenntnissen, um später in einem neuen Chat fortsetzen zu können" alles entsteht.
Ganz genau. Ich habe meist auch eine Regel, die noch ein permanentes Learnings.md file füttert und welches dann abundzu in whisking.md zusammenaggregiert wird.
Dabei hilft das LLM am Ende eben auch mit, möglichst viel Kontext mit möglichst wenig tokens verfügbar zu haben. Und ja, eine der Regeln ist auch, dass das llm mich nach einen signoff fragt, bevor es des aktuellen task als erledigt markiert und weitermacht.
Irgendwann im laufe des Projektes kommen dann halt auch Regeln dazu wie das locale building und testen zu funktionieren hat. Die neueren Versionen sind besser geworden aber alte Versionen haben sich gerade Client/Server Architekturen gern mal in den Fuß geschossen, wenn sie den Server gestartet haben und den Output nach dem exit analysieren wollten…
Ja, es sind halt kleine Dummerchen LLMs die man an die Hand nehmen muss um von dem WAS sie können zu profitieren.
Die können halt nicht logisch denken/vorhersehen. Die können nur mit dem gegebenen Context von einer oder mehreren Quellsprachen den Text in einen anderen Zustand transformieren. (Je nach Heat nichtmal deterministisch) aber wir Menschen können aus diesem Mechanismus eine turingvollständige Maschine bauen. Das ist der Job des promptes.