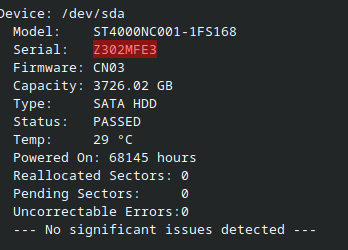
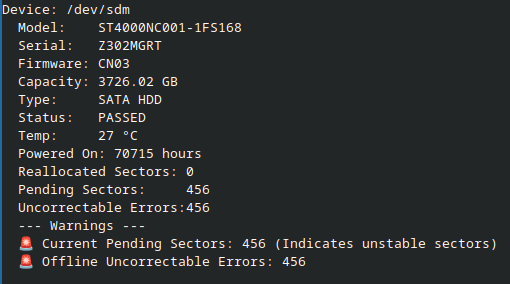
Reminder that SMART is not magic, in my experience, disks are dead long before SMART stops reporting them as 'PASSED'.
I actually came across the perfect example today: Two disks in my backup server are having issues, one is clearly broken, the other gave 2 checksum errors.
Despite this, neither disk is 'failed' according to SMART, one has 456 offline uncorrectable errors / pending sectors, the other one is fine.
Don't rely on broken hardware to tell you that it's broken.
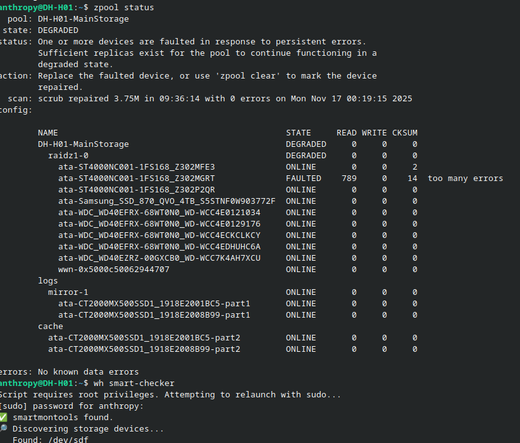
 it's a mixed array anyway, it wouldn't be a Redundant Array of INEXPENSIVE Disks if I stuffed it full of new enterprise drives haha (smh companies always get this wrong)
it's a mixed array anyway, it wouldn't be a Redundant Array of INEXPENSIVE Disks if I stuffed it full of new enterprise drives haha (smh companies always get this wrong)