🌕 將 LLM 編譯為巨核心:實現低延遲推論之路
➤ 透過自動化編譯,大幅提升大型語言模型推論效率
✤ https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
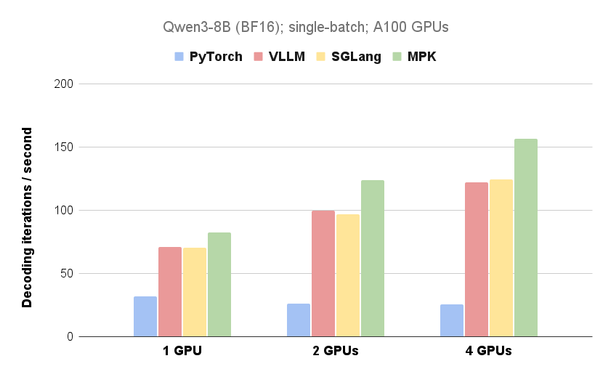
卡內基美隆大學、華盛頓大學、柏克萊大學、NVIDIA 及清華大學的研究團隊開發了 Mirage Persistent Kernel (MPK),這是一個能夠自動將多 GPU 大型語言模型的推論過程轉化為高效巨核心的編譯器和運行時系統。MPK 透過融合計算與通訊,消除核心啟動開銷,並最大限度地重疊計算、數據加載和 GPU 之間的通訊,大幅降低了 LLM 推論的延遲,在某些情況下可提升 1.2 到 6.7 倍。
+ 哇,這真是一個突破性的技術!如果能有效降低 LLM 的延遲,將會對許多應用產生深遠的影響。
+ 聽起來很複雜,但如果真的像他們說的那樣易於使用,那將會是開發者們的一大福音。
#人工智慧 #大型語言模型 #GPU #編譯器 #效能優化
➤ 透過自動化編譯,大幅提升大型語言模型推論效率
✤ https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
卡內基美隆大學、華盛頓大學、柏克萊大學、NVIDIA 及清華大學的研究團隊開發了 Mirage Persistent Kernel (MPK),這是一個能夠自動將多 GPU 大型語言模型的推論過程轉化為高效巨核心的編譯器和運行時系統。MPK 透過融合計算與通訊,消除核心啟動開銷,並最大限度地重疊計算、數據加載和 GPU 之間的通訊,大幅降低了 LLM 推論的延遲,在某些情況下可提升 1.2 到 6.7 倍。
+ 哇,這真是一個突破性的技術!如果能有效降低 LLM 的延遲,將會對許多應用產生深遠的影響。
+ 聽起來很複雜,但如果真的像他們說的那樣易於使用,那將會是開發者們的一大福音。
#人工智慧 #大型語言模型 #GPU #編譯器 #效能優化