Word censorship and evasion
https://www.babbel.com/en/magazine/tiktok-language
What you get is a different and quickly evolving language while the old language is being unalived.
Word censorship and evasion
https://www.babbel.com/en/magazine/tiktok-language
What you get is a different and quickly evolving language while the old language is being unalived.
The EU is currently congratulating itself because it managed to get a hashtag banned on TikTok in relatively little time.
LLMs encode the meanings of terms as vectors along many semantic dimensions in a semantic space ("latent space"). A concept, then, is a position in that space with a certain diameter — a kind of fuzziness or vagueness.
When I type something into ChatGPT or a recommender system, the input is broken down into tokens, and these tokens are mapped to such vectors.
“I want pizza” becomes:
["I", "want", "pizza", "."]
The tokens are then internally mapped to embeddings, like:
“cat” → [0.24, -1.12, 0.58, …]
“dog” → [0.22, -1.09, 0.60, …]
That is, a list of numbers (often normalized between -1 and 1). But usually there are far more dimensions than shown here — an embedding typically has thousands of dimensions.
The latent space — the semantic space — is self-organizing. That happens during training. We don’t know what each dimension in the space represents.
The encoding has meaning. When look at the vectors for "man" and "woman" and for "king" and "queen", we can substract "man" from "woman" and "king" from "queen" and compare the difference vectors. They are almost, but not quite the same – because the difference between these words to us is almost, but not quite the same, in meaning.
LLMs use these embeddings and their internal model to “compute the next output token.”
Recommender systems use such embeddings to compare vectors and find things that are similar to the thing we already have.
So a recommender learns everything that’s relevant to a user, and a modern recommender represents the user through a collection of vectors:
"Interested in travel, digital policy, databases, bikes."
These are all concepts that may also be near other concepts in the space.
At the same time, the recommender classifies content in the same space, and can find content that lies close to one of the user’s sub-interests — or content that’s new, but still compatible.
A modern recommender separates a user’s interests into distinct areas and can decide what the user is interested in right now — meaning, which of the various user interests is currently active. Then, this time, it might only serve database content, and next time only bike content.
A modern recommender will also deliberately serve content that almost — but not quite — matches the user’s interests, to test how wide the bubble is around the center of that interest vector. So a bike session might also include urbanism, city development, and other nearby topics, and the recommender will watch carefully to see what kind of response that triggers — refining its recommendations based on that feedback.
A modern recommender will also know where the available content clusters are and prioritize content that is both relevant to the user and performs well or has current production capacity. In other words, where user interest and available content overlap well.
And a modern recommender will reevaluate every twenty minutes (“Pomodoro”, or “method shift” in educational theory) and attempt to shift the theme — to test whether another known interest can be reactivated.
That’s how TikTok works.
You can ban a hashtag on TikTok (“#skinnytok”).
But as long as related concepts are marketable and socially accepted — or even demanded — that won’t prevent anything.
As soon as you browse categories like “model,” “weight loss,” “fitness,” or “slim,” TikTok will slowly and systematically pull you into the same region, and the end result will be the same.
The actual language, the meaning, is encoded in the tokens of the latent space of the model, not in the words that are used (or prohibited).
And the content density in the models coordinate system will gently push things into certain clusters. If you feed the system with the right interests, you will always drift – relatively quickly even – into the same neighborhood and then learn their current slang to get there with a single word.
No matter what the word actually is.
A similar example, using GenAI instead of a recommender:
"Draw a superheroine, an Amazon warrior that can fly and deflect bullets, running over a battlefield in the first world war."
These 21 words do not say "Wonder Woman", they do not even go near comics, DC, or similar things.
Yet they draw a thousand-dimensional hyberbubble in latent space, the totality of knowledge known to ChatGPT, and the end result leaves just one choice – produce this blatant copyright violation.
I can trigger content with intent, not even going near the keywords that would be associated with it.
This is how jailbreaks work in LLMs, and that is also how you jailbreak Tiktok bans.



The EU is currently congratulating itself because it managed to get a hashtag banned on TikTok in relatively little time.
LLMs encode the meanings of terms as vectors along many semantic dimensions in a semantic space ("latent space"). A concept, then, is a position in that space with a certain diameter — a kind of fuzziness or vagueness.
When I type something into ChatGPT or a recommender system, the input is broken down into tokens, and these tokens are mapped to such vectors.
“I want pizza” becomes:
["I", "want", "pizza", "."]
The tokens are then internally mapped to embeddings, like:
“cat” → [0.24, -1.12, 0.58, …]
“dog” → [0.22, -1.09, 0.60, …]
That is, a list of numbers (often normalized between -1 and 1). But usually there are far more dimensions than shown here — an embedding typically has thousands of dimensions.
The latent space — the semantic space — is self-organizing. That happens during training. We don’t know what each dimension in the space represents.
The encoding has meaning. When look at the vectors for "man" and "woman" and for "king" and "queen", we can substract "man" from "woman" and "king" from "queen" and compare the difference vectors. They are almost, but not quite the same – because the difference between these words to us is almost, but not quite the same, in meaning.
LLMs use these embeddings and their internal model to “compute the next output token.”
Recommender systems use such embeddings to compare vectors and find things that are similar to the thing we already have.
So a recommender learns everything that’s relevant to a user, and a modern recommender represents the user through a collection of vectors:
"Interested in travel, digital policy, databases, bikes."
These are all concepts that may also be near other concepts in the space.
At the same time, the recommender classifies content in the same space, and can find content that lies close to one of the user’s sub-interests — or content that’s new, but still compatible.
A modern recommender separates a user’s interests into distinct areas and can decide what the user is interested in right now — meaning, which of the various user interests is currently active. Then, this time, it might only serve database content, and next time only bike content.
A modern recommender will also deliberately serve content that almost — but not quite — matches the user’s interests, to test how wide the bubble is around the center of that interest vector. So a bike session might also include urbanism, city development, and other nearby topics, and the recommender will watch carefully to see what kind of response that triggers — refining its recommendations based on that feedback.
A modern recommender will also know where the available content clusters are and prioritize content that is both relevant to the user and performs well or has current production capacity. In other words, where user interest and available content overlap well.
And a modern recommender will reevaluate every twenty minutes (“Pomodoro”, or “method shift” in educational theory) and attempt to shift the theme — to test whether another known interest can be reactivated.
That’s how TikTok works.
You can ban a hashtag on TikTok (“#skinnytok”).
But as long as related concepts are marketable and socially accepted — or even demanded — that won’t prevent anything.
As soon as you browse categories like “model,” “weight loss,” “fitness,” or “slim,” TikTok will slowly and systematically pull you into the same region, and the end result will be the same.
The actual language, the meaning, is encoded in the tokens of the latent space of the model, not in the words that are used (or prohibited).
And the content density in the models coordinate system will gently push things into certain clusters. If you feed the system with the right interests, you will always drift – relatively quickly even – into the same neighborhood and then learn their current slang to get there with a single word.
No matter what the word actually is.
A similar example, using GenAI instead of a recommender:
"Draw a superheroine, an Amazon warrior that can fly and deflect bullets, running over a battlefield in the first world war."
These 21 words do not say "Wonder Woman", they do not even go near comics, DC, or similar things.
Yet they draw a thousand-dimensional hyberbubble in latent space, the totality of knowledge known to ChatGPT, and the end result leaves just one choice – produce this blatant copyright violation.
I can trigger content with intent, not even going near the keywords that would be associated with it.
This is how jailbreaks work in LLMs, and that is also how you jailbreak Tiktok bans.
@phreaknerd @isotopp Agreed, but this cuts 90+% of the financing. So the algorithms have to become simpler and less data intensive. So the balance will be at a better point.
Another idea I had a long time ago:
If an algorithm shows you a post you didn't subscribe to, the owner of the algorithm becomes fully responsible (financially and legal) for the content of said post as if he were the editor.
This would add another balance point with the algorithm having to assess dangers of a post in comparison to it's potential use.
@masek @phreaknerd @isotopp how about just not having ad-financed services?
I appreciate the basic idea of "ads finance services to poor people who couldn't afford them otherwise", but.. let's face it: That model has failed us utterly.
@jollyorc You've got my vote. I consider advertisement as a blight. Any advertisement is a business at the expense of third parties.
But that ban will be very difficult.
@masek @jollyorc @phreaknerd @isotopp you can also just use your own customized mastodon timeline algorithm
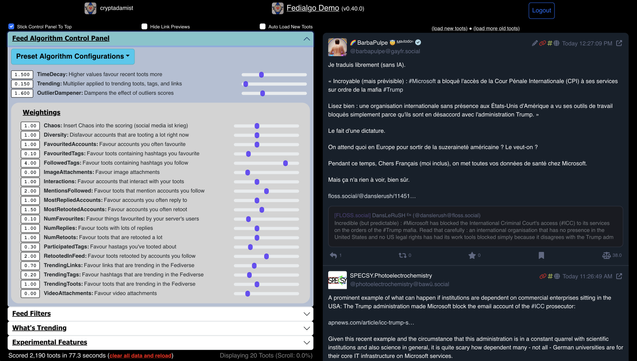
Attached: 1 image Ω🪬Ω #FediAlgo, the customizable timeline algorithm / filtering system for your Mastodon feed, is now deployed on Github Pages and can be used from your web browser. * Link: https://michelcrypt4d4mus.github.io/fedialgo_demo_app_foryoufeed/ * Code: https://github.com/michelcrypt4d4mus/fedialgo_demo_app_foryoufeed * Video of FediAlgo in action: https://universeodon.com/@cryptadamist/114395249311910522 #activitypub #algorithm #algorithmicFeed #algorithmicTimeline #Fedi #FediTips #FediTools #Fediverse #Feed #FOSS #Masto #MastoAdmin #Mastodon #mastohelp #MastoJS #nodejs #nod #opensource #SocialWeb #timeline #TL #webdev
@isotopp and quite frankly I wouldn't know what to do without the content recommendations.
I can leave YouTube running for an entire day and just get more and more content thrown at me to learn from, Vs actively having to hunt out stuff.
It's literally the main way to discover new channels or relevant information.

@isotopp While I am quite convinced that the ban can be circumvented, I still think that banning the word will throttle traffic to videos posted by anorexic models for some time.
Which, considering how social networks work, may be sufficient.
@dl2jml I just tried TikTok again and no, about five searches in I had a stream full of 50 kg women (models, thigh gap, collarbone, BMI, weight loss, skinny).
"Thigh gap" was blocked and linked to a help line, but greatly influenced FYP. The others were not blocked. Clean thinspo stream in <5 minutes.
The recommender targets very well, you set an ana context, you get ana propaganda. You like these videos, subscribe these people and the interest is locked in.
@dl2jml That is not what I did.
I searched for concepts that are related to or biased for underweight women and got my FYP predisposed to serve me only underweight women the same way searching for a hashtag would do.
There never was a hashtag involved, though. TikTok is not Tumblr.
TikTok has inferred my preference and created a FYP from what it learned from my searches and likes and watch times. It will now continue to do so for as long as their recommender thinks this will keep my eyeballs on their stream.
Banning a hashtag does not change that nor does it slow the recommender down . Again, this is not 2012 and we're not on Tumblr any more. The mechanism underneath is far more capable.
@isotopp I have no way to know what you exactly did.
But let us start again. A particular hashtag was banned. Presumably, it was popular or it would not have been chosen for a ban. Then, by the definition of "popular", it means that large numbers of users were searching using that hashtag. Therefore banning it will have some of these users' searches run afoul. I don't know which percentage.
Will that be sufficient? Certainly not. But I never said so.