Some signs of #AI model collapse begin to reveal themselves - https://www.theregister.com/2025/05/27/opinion_column_ai_model_collapse/ "Prediction: General-purpose AI could start getting worse" indeed

@glynmoody Faster!
@fgbjr it will
"I used AI to....", is nothing more than, "Listen I'm not an asshole but....", for the 21st Century.
@glynmoody No, no
Reality is at fault.
Reality is at fault.
@withaveeay always
@glynmoody Let's hope for the best.
@art_histories i think we can...
@glynmoody
I was one of the first to study #AI in college back in the mid-80s.
What people refer to as "AI" today is nothing more than "Deep Database Scrubbing" (which is why it requires so much power.)
It constantly scours billions of data sources and "makes assumptions" based on the number of links/connections between two bits of info. Garbage_In/Garbage_Out.
It doesn't test for accuracy, and the more unreliable the sources, the more unreliable the conclusions.
Collapse is inevitable.


@MugsysRapSheet @glynmoody using an AI image kinda defeats the point here.
@glynmoody Sounds like what @jensorensen explained beautifully in this cartoon…
@stuartl @jensorensen nice: mad cow disease had occurred to me too, but I can't draw...
@glynmoody @stuartl @jensorensen
My analogy was inbreeding, but mad cow is similar.
https://mstdn.social/@stekopf/114581174083947454
Sepia Fan (@stekopf@mstdn.social)
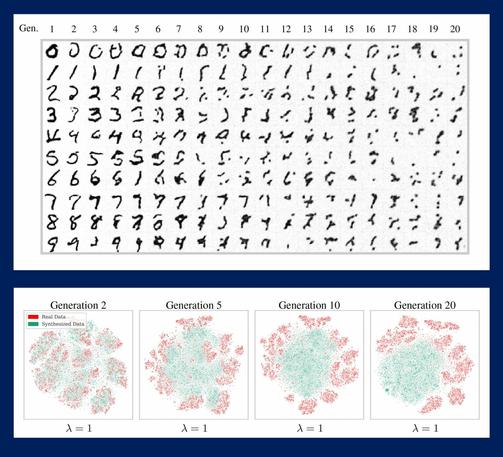
Attached: 2 images @jensorensen@mastodon.social Thank you. I ended up at the University page: "Self-Consuming Generative Models Go MAD" https://news.rice.edu/news/2024/breaking-mad-generative-ai-could-break-internet The subtitle "Training #AI systems on synthetic data could include negative consequences" is quite the understatement if one looks at the left image. 🤪 Left image shows #LLM deterioration when trained with artificial data. Right image shows the same when trained with prepared artificial data (see link for details). Even there 20% of the info gets distorted quickly.
@glynmoody #AI swallows its own vomit.
@glynmoody haha, reaching the point of no return, eh, not garbage in garbage out, but more like competing streams of garbage. So predictable.
@wrath0110 except to its investors
@glynmoody
Not exactly the sharpest tool in the shed isn't he?
The reason why ai search isn't working properly anymore is in the /robots.txt files. Except on The Register. 😄
Not exactly the sharpest tool in the shed isn't he?
The reason why ai search isn't working properly anymore is in the /robots.txt files. Except on The Register. 😄
@NicholasLaney @glynmoody I would be surprised if they respected robots.txt if they are quite happy to do mass pirating and copyright infringement to train the models
@daz @NicholasLaney @glynmoody
The scrappers haven't been following robots.txt for a while.
https://www.technologyreview.com/2025/02/11/1111518/ai-crawler-wars-closed-web/

@NicholasLaney many bots ignore robots.txt, so I don't think it's that...
I think the only way people can speed up the collapse is by finding as many ways to poison the content they create as possible. AI devs will never voluntarily limit AI. It needs to be made a nightmare for them create training sets.
@glynmoody neologism I'm working to kick into play: #gigaGIGO - like normal GIGO, but at the 10^9 scale.
@rowat_c sounds good
@glynmoody The author is showing extraordinary arrogance to suggest that the he is the only one who is calling this out. Many of us have been predicting for months, if not years, that letting AI feed upon its own output will end in farce.
@KimSJ @glynmoody Yep. It should be obvious to anyone who isn't susceptible to hype, that flooding the internet with slop will only poison the training data for future iterations of genAI, degrading the quality of their output over time. The models will increasingly end up feeding on *each other's* error-strewn output.
These shitty LLMs we have now? They're the pinnacle of how good such models will ever get, no matter how many more billions are "invested" in their development.
@ApostateEnglishman @KimSJ @glynmoody
we used to call it GIGO
@samiamsam @KimSJ @glynmoody Yep. Only in this case, on an industrial scale - and then we feed all that garbage *back in* to the machines and get even worse garbage back out.
We keep doing this until everything is garbage.
@ApostateEnglishman @samiamsam @glynmoody
I proposed at an early point in this farce that regulators should mandate that any content produced by AI must be tagged as such. This would have allowed future AI iterations to disregard it. Sadly, I think that ship has well and truly sailed now.
I proposed at an early point in this farce that regulators should mandate that any content produced by AI must be tagged as such. This would have allowed future AI iterations to disregard it. Sadly, I think that ship has well and truly sailed now.
@KimSJ @ApostateEnglishman @samiamsam @glynmoody These kind of rules never stopped spam, though. Companies will just ignore it, just as they are ignoring any form of privacy legislation.
@ApostateEnglishman @KimSJ @glynmoody There's even a cartoon satire of the process of "Model Autophagy Disorder" ("MAD", as in "MAD cow disease"):

@ApostateEnglishman @dedicto @KimSJ @glynmoody wishful thinking but if "big AI" has the political power to bypass all copyright, then it should have the political power to mandate that all AI generated content be adequately watermarked so that it can be avoided on the next pass. Then it would become possible for your favourite open search engine to filter all such content from your search results
@chris_e_simpson
They may well have to do that anyway, to stop it marking its own homework; IIUC people are beginning to see its search functionality starting to degrade.
@KimSJ many of us have, but he's a columnist, he's just generalising his own experience
@glynmoody A perfect description of what columnists do!
@KimSJ I speak as one...
@glynmoody "My mind is going... I can feel it." - HAL 9000
@profdc9 always was deep that film

@glynmoody why is anybody even surprised about this?
@burningTyger because VCs need us to believe the contrary
@glynmoody They have just about reached the limits of how much training they can use with existing data collection methods and artificial refinement methods.
The irony is, one way they could exponentially improve their model training is the one thing that still won't occur to them: pay people to actually write stuff for it with consistent quality and formatting instead of just stealing data from all over the Internet. They could also get higher quality out of smaller models. And then they wouldn't have to pay Meta/etc to help steal data for them.
But they'll die before they'll consider doing it that way, lol. And that may just happen at the rate they're going. I just hope the pretend LLMs are AI when they aren't crash doesn't take others out with it.
@nazokiyoubinbou they are already paying people to write stuff: journalists and others are doing this because they need the money...
@glynmoody Not really, no.
I'm talking about actually paying people to sit down and write actual training data. I don't just mean taking journalist's articles and feeding them in or that sort of thing. I mean writing data specifically for the models.
@nazokiyoubinbou yes, that is what they are doing: writing to order, specifically for ai
@glynmoody A little anecdote. A year ago my mom got me a Bird Buddy that takes photos and videos of birds at the feeder. Fun little gadget which also id’s birds. Part way through the year they updated their app to include/upgrade AI. And the id’s have gotten much worse. Purple finches, which we see multiple times a day, are being called house sparrows. American goldfinches are named as lesser goldfinches. These are easily identified, not even close.
@madrobin amazing...
@madrobin Huh. I can't tell the goldfinches apart from pics, and asked at Wild Birds Unlimited and got an answer that doesn't always apply.
I only know I have lessers because the Merlin app id's their vocalizations.
How *do* you tell them apart?
@solitha Their bills are different colors and the male lessers have a black head and dark back, not just a black cap. The females are hard, but the AI is mixing up the males.
@glynmoody it's already ruined the Internet, much like the "internet of things"
Hands up anyone that needs a kettle connected to the internet to act as a security risk...
Cos it's no good for anything else u
Hands up anyone that needs a kettle connected to the internet to act as a security risk...
Cos it's no good for anything else u
@cockneylaurie it's all about startups and business models, not need...
@cockneylaurie @glynmoody I had an LED strip light that requires Internet. This was so nonsensical that I never used it. I couldn't give it back unfortunately because I already cut it. A strip light with Internet. Why? Why?
@glynmoody you mean it's POSSIBLE for general AI to get worse???
@UkeleleEric oh yes...
@glynmoody Interesting that the article's examples of AI "getting worse" are actually AI doing exactly what it was designed to do: create passable language summaries of the crap that's out there.
What they want it to do—separate truth from fiction, valuable data from useless data—is not something it was designed to do nor is it capable of doing. That requires the hard work of research (journalistic, academic, professional) that people seem to naively believe they can skip if they use AI to write their papers for them.