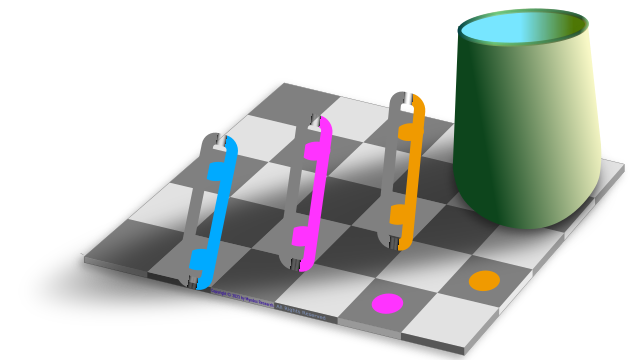
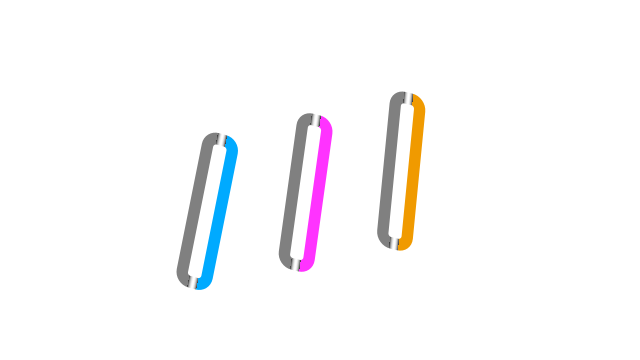Most folks with "normal" colour vision will say they perceive yellow, green, red and blue pegs hanging on a line here.
Yet the pixel samples shown along each peg illustrate that not a single point on each peg is "diagnostic" of its perceived body colour.
How do we perceive the pegs as solid body colours despite so much variation in the samples?
Nobody knows, but we can speculate that the visual system somehow integrates the samples to produce a percept of body colour.
An even more challenging question is how we perceive different parts of each peg to be translucent, opaque, shadowed and dirty from the image variations.