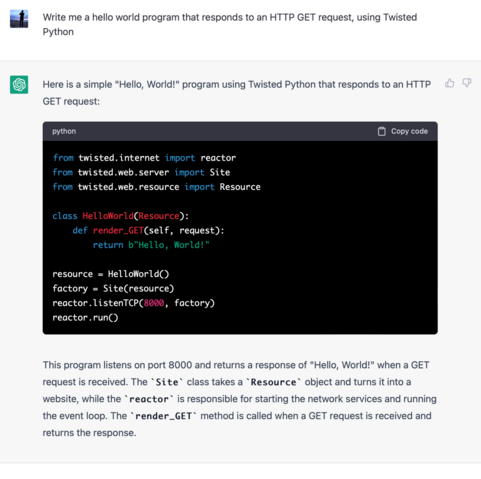
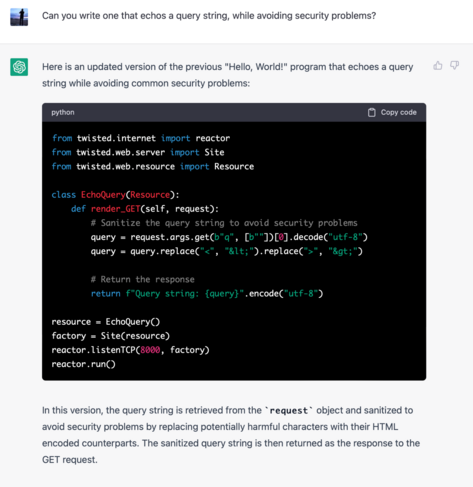
If you try to use ChatGPT and similar language models as search engines they're going to lie to you, a lot, and you're at risk of writing off the whole space as hype
The trick is to learn what they're useful for and how to take advantage of them, which is actually quite a lot of work