@njakob
Irgendwo hab ich auch noch einen Collegeblock, auf dem ein halbes Kapitel steht, das musste ich dann mühsam abtippen.
Wenn die neue (K)Ubuntu Version draußen ist, will ich meinem Rechner ne neue Platte gönnen (wir sprachen ja neulich schon davon) und nochmal alles neu und vernünftig aufspielen.
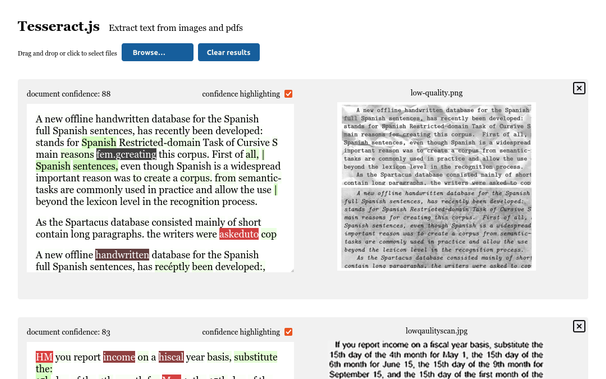
Hatte vor langer Zeit mal damit angefangen, Flachbettscanner und #TesseractOCR sauber aufeinander abgestimmt aufzusetzen und Tesseract dann u.a. an meine beiden mechanischen Schreibmaschinen zu "gewöhnen". Das klappt ganz gut und der ausgelesene Fließtext ist nahezu fehlerfrei.
Selbiges will ich dann, wenn ich zumindest meinen Haufen Schmerzmittel los bin, auch für Handschrift einrichten. Das lohnt sich aber erst dann, wenn meine Sauklaue wieder wie gewohnt schlampig aussieht.
Das ist dann für mich ein guter Mittelweg... egal womit geschrieben, einfach durch den Scanner jagen und fertig is.
Naja, Du bist es ja gewohnt, das meiste eben auf dem Fon oder dem Tablet zu machen. Dann würde ich wohl auch so arbeiten, wie Du es jetzt tust. Ich habe ja den zweifelhaften Luxus meines gepflegten Durcheinanders und muss mir dafür ein Konzept zusammenfummeln. 😀
Mal sehen, worauf es dann hinauslaufen wird. Ganz ablassen vom Zettelgeschmiere kann ich wohl eher nicht. 😉