Ivan Fioravanti ᯅ (@ivanfioravanti)
tensor-parallel을 사용하려면 num_k_heads와 num_v_heads가 3으로 나누어떨어져야 할 것 같아 머신 4대가 필요하지 않겠냐고 @angeloskath에게 확인하는 기술적 고민. 이 경우 M5 Ultra 2대를 추가로 구입해야 할 수도 있다는 인프라·모델 병렬화 관련 논의입니다.
Ivan Fioravanti ᯅ (@ivanfioravanti)
tensor-parallel을 사용하려면 num_k_heads와 num_v_heads가 3으로 나누어떨어져야 할 것 같아 머신 4대가 필요하지 않겠냐고 @angeloskath에게 확인하는 기술적 고민. 이 경우 M5 Ultra 2대를 추가로 구입해야 할 수도 있다는 인프라·모델 병렬화 관련 논의입니다.
Alex Cheema - e/acc (@alexocheema)
GLM-4.7-Flash를 4대의 M4 Pro Mac Mini에서 Exolabs를 통해 실행 중이라는 보고. Thunderbolt 기반 RDMA와 MLX 백엔드를 활용한 텐서 병렬화로 초당 약 100토큰 처리 성능을 기록하며, Exolabs에서 최적화를 진행해 동일 구성에서 약 200 tok/sec 달성을 목표로 하고 있음.
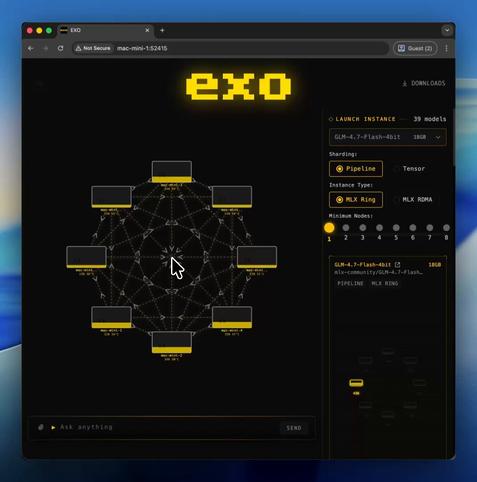
Running GLM-4.7-Flash on 4 x M4 Pro Mac Minis using @exolabs. Uses tensor parallelism with RDMA over Thunderbolt & MLX backend (h/t @awnihannun). Runs at 100 tok/sec. We're working on optimizing this at @exolabs. Aiming to hit ~200 tok/sec on this setup soon.
Bài hỏi về việc sử dụng Tensor Parallel (TP) khi không tất cả GPU là đồng loại. Người dùng muốn biết liệu có thể chia 50% tải cho RTX 6000 và 50% cho 4x RTX 3090 không? Đây là cách tiết kiệm khi chưa có GPU thêm. #TensorParallel #GPU #LocalLLaMA #TốiưuHệThống #TensorParallel #GPU #LocalLLaMA #OptimizeSystem
https://www.reddit.com/r/LocalLLaMA/comments/1pt0vbz/tensor_parallel_with_some_gpu_but_not_all/
Strix Halo thử nghiệm batching với tensor parallel và pipeline parallel trên vllm. Kết quả cho thấy TP (tensor parallel) cho hiệu năng tốt hơn PP (pipeline parallel). #AI #LLM #LocalLLaMA #StrixHalo #TensorParallel #PipelineParallel #TríTuệNhânTạo #MôHìnhNgônNgữ
https://www.reddit.com/r/LocalLLaMA/comments/1p8nped/strix_halo_batching_with_tensor_parallel_and/
