Spatial prediction meets machine learning with mlr3 💡🌍
This blog post by Marvin Ludwig also includes tips on autocorrelation, extrapolation & more.
Spatial prediction meets machine learning with mlr3 💡🌍
This blog post by Marvin Ludwig also includes tips on autocorrelation, extrapolation & more.
The #mlr3 book has a new chapter on validation and internal tuning (e.g. early stopping): https://mlr3book.mlr-org.com/chapters/chapter15/predsets_valid_inttune.html #rstats
The chapter describes some newly introduced features in mlr3 that allow you to define validation splits for iterative learning procedures such as boosting or neural networks, even in complex learning pipelines. Furthermore, you can now easily combine early stopping with standard hyperparameter tuning.



Reminder that you can now preorder the #mlr3 book on machine learning in #rstats at amazon (https://amzn.eu/d/934kjEF) or from the publisher with a 20% discount code AFL04 at http://www.routledge.com/9781032507545
It's pretty cool™
Excited to announce that “Applied Machine Learning Using mlr3 in R”, will be published by Chapman and Hall on 19 Jan. Authored and edited by the mlr core team, our book provides a practical guide to #MachineLearning in #RStats using our #mlr3 software.

mlr3 is an award-winning ecosystem of R packages that have been developed to enable state-of-the-art machine learning capabilities in R. Applied Machine Learning Using mlr3 in R gives an overview of flexible and robust machine learning methods, with an emphasis on how to implement them using mlr3 in R. It covers various key topics, including basic machine learning tasks, such as building and evaluating a predictive model; hyperparameter tuning of machine learning approaches to obtain peak perfor
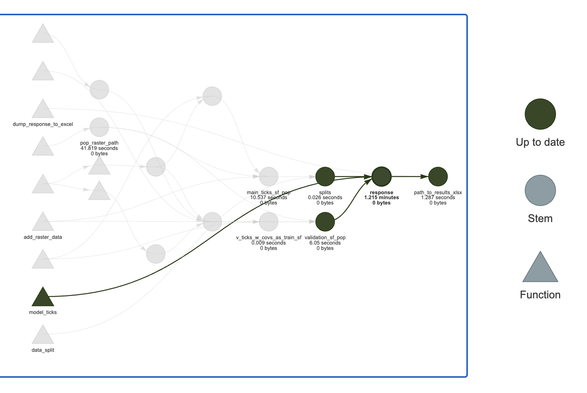
Pipeline tools coordinate the pieces of computationally demanding analysis projects. The targets package is a Make-like pipeline tool for statistics and data science in R. The package skips costly runtime for tasks that are already up to date, orchestrates the necessary computation with implicit parallel computing, and abstracts files as R objects. If all the current output matches the current upstream code and data, then the whole pipeline is up to date, and the results are more trustworthy than otherwise. The methodology in this package borrows from GNU Make (2015, ISBN:978-9881443519) and drake (2018, <doi:10.21105/joss.00550>).

