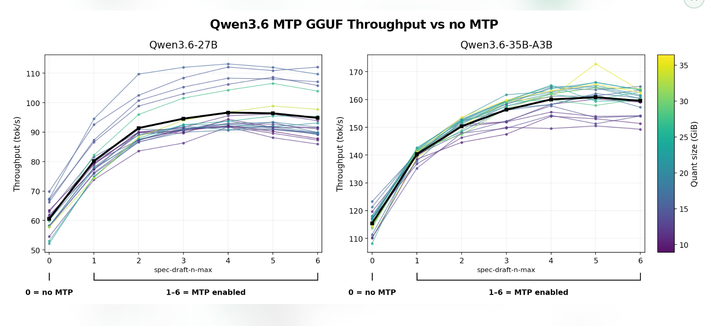
There is a new technique to speed up token generation called MTP. It predicts several future tokens, then the main model verifies them in parallel.
There is a catch however: it does require more VRAM. #GPUHiddenTax
This means that on low vram GPUs, it leads to the opposite, or at least drastically shorten context size to keep up.
⚠️ The models do not hallucinate any less.